
1. CNN(Convolutional Neural Networks) 구조
2. Convolutional Layer
가장 먼저, CNN에서 가장 주요한 구성 요소인 Convolutional layer(합성곱 층)의 구성 요소와 작동 원리를 알아보자.
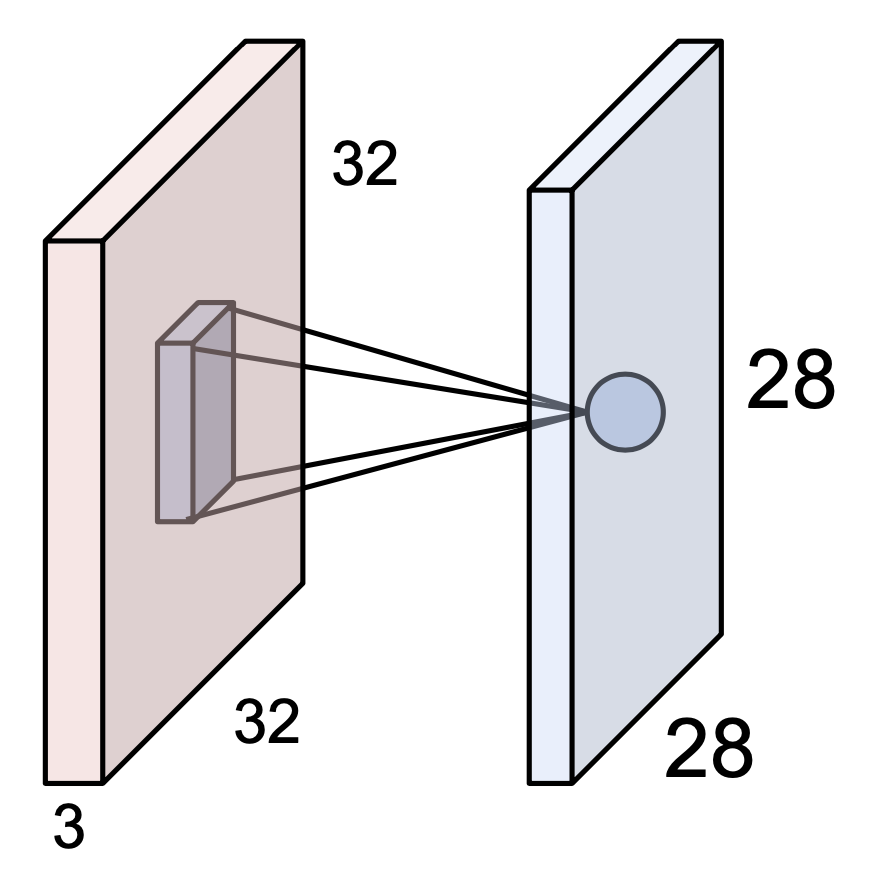
기본적으로 Convolution Layer에는 input값인 이미지와 필터(= 합성곱 커널:convolution kernel)가 있다.
위의 그림처럼, 필터(= 커널: kernel)가 이미지의 위에서부터 차례대로 내려오면서(sliding) dot products를 해나간다. 다시 말해 32 * 32 * 3의 크기의 이미지에 5 * 5* 3의 필터로 차례대로 훑고 내려오면서 5 * 5* 3(즉 75번)의 dot product 연산을 하는 것이다. 또한 각각의 dot product 결과로 하나의 숫자를 return 한다. 즉, 필터가 위치해있는 하나의 location 당 하나의 숫자로 표현되는 것이다.
이때 convolution layer(합성곱 층)의 뉴런은 입력 이미지의 모든 픽셀에 연결되는 것이 아니라, colvolution layer 뉴런의 수용장 안에 있는 픽셀에만 연결된다는 특징이 있다. CNN에서 필터의 크기 (위의 경우에는 5 * 5 * 3)는 파라미터의 수를 의미하며 하나의 필터는 하나의 activation map(= 특성 맵 : feature map)을 생성한다.
따라서 위와 같이 왼쪽의 input 이미지에 2개의 필터를 적용했다면 오른쪽 그림과 같이 2개의 activation maps가 생성된다.
input으로 들어온 이미지를 activation의 관점에서 representation을 하면 오른쪽과 같이 새로운 형태의 이미지로 변환되는 것이다. 이때 새로 생성된 activation maps의 depth는 적용한 필터의 수와 동일하다. 이렇게 생성된 activation map을 다음 layer의 input값으로 전달된다.
그렇다면 32 * 32의 크기였던 input 이미지가 어떻게 어떻게 28 * 28로 사이즈가 변한 것일까? 그 방법과 관련해서 stride와 pooling 기법에 대해 알아보자.
3. Stride
위의 그림과 같이 input으로 7 * 7 크기의 이미지가 들어올 때, 여기에 3 * 3 필터를 적용해보자.
7 * 7 input
3 * 3 filter
stride 1
5 * 5 output
stride는 한 필터와 다음 필터 사이의 간격이라고 생각하면 된다. 예를 들어 위의 그림과 같이 stride를 1로 설정했다는 것은 필터와 다음 필터 간격이 1이라는 의미가 되고 1칸씩 가로 & 세로 방향으로 이동하면서 이미지에 필터가 적용된다. 다시 말해, 7 * 7의 크기를 가진 이미지에 3 * 3의 크기를 가진 필터를 stride 1로 적용하면 가로 & 세로 각각 총 5칸씩을 이동할 수 있으므로 output으로 5 * 5의 크기를 가진 activation map이 생성되는 것이다.
7 * 7 input
3 * 3 filter
stride 2
3 * 3 output
동일한 방법으로 이번에는 stride를 2로 필터를 적용해보자.
7 * 7 이미지에 3 * 3 필터를 가지고 2칸씩 이동하면서 적용해보면 그 결과 3 * 3의 크기를 가진 activation map이 형성된다.
이러한 원리로 output size에 대해 하나의 공식을 도출해낼 수 있다.
이때 N은 이미지의 (w, h), F은 필터의 (w, h)를 의미한다. 이전의 예시를 이 공식에 대입해보자. 7 * 7의 크기를 가진 이미지에 3 *3의 필터를 stride를 1로 적용한다면 (7 - 3) / 1 + 1이므로 output으로 5가 도출된다. 두 번째로 7 * 7의 이미지에 3 * 3의 필터를 stride 2로 적용하면 3이 도출된다.
그렇다면 7 * 7의 이미지에 3 * 3 필터를 stride 3으로 적용하면 어떻게 될까? 위의 공식에 대입해보면 ( 7 - 3 ) /3+1로 2.33의 값이 나옴을 알 수 있다. 2.33의 숫자는 애매하지 않은가?
위의 그림같이 7 * 7 이미지에 3 *3 필터를 3칸씩 이동하면서 적용해보면 3번째 이동 시 필터를 적용할 칸이 부족한 것을 볼 수 있다. 따라서 이와 같은 경우에는 stride3을 적용할 수 없게 된다. 이러한 상황을 해결할 수 있는 방법으로 zero padding기법이 있다.
3-1. Zero Padding
zero padding은 0의 값을 가진 픽셀로 해당 이미지를 둘러싸 주는 것이라고 생각하면 된다. 이렇게 padding을 적용하면 7 * 7 이미지에 3 *3 필터를 stride3로 적용할 수 있게 된다.
또한 padding을 적용하면 사이즈를 보존하는 효과를 얻을 수 있다.
padding을 이용해서 사이즈를 보존하는 것이 어떠한 의미를 가지며 왜 중요한 것일까?
CNN에서는 layer가 진행될수록 위의 그림처럼 사이즈가 점점 줄어들게 된다(shrinks volumes). 만약 volume이 빠르게 줄어들어 0이 되어 버리면 더 이상 CNN을 적용할 수 없는 상태가 된다. 이러한 문제를 해결하기 위해 padding을 이용하여 너무 빠르게 사이즈가 줄어들지 않게 보존해주는 것이다.
4. Pooling Layer
CNN에서는 padding을 이용해서 사이즈를 보존해주되, 동시에 사이즈를 점점 줄어나가는 것이 중요하다. 따라서 pooling layer에서는 down sampling을 담당한다.
위의 그림과 같이 pooling layer에서 down sampling을 진행한 결과 사이즈가 절반으로 줄어들었음을 알 수 있다. 이러한 작업은 각 activation map에 독립적으로 적용되며 이때 depth는 그대로 유지된다.
➰ Max Pooling
pooling 방법 중 가장 많이 쓰이는 것은 Max pooling이다. 왼쪽 그림과 같이 4 * 4 이미지에 2 * 2의 필터를 stride2로 적용하여 빨간, 초록, 노랑, 파란색으로 각 영역을 구분해준다. 이때 각 영역에서 가장 큰 값만 추출하는 방법이 Max pooling이다. 그 결과 오른쪽 그림과 같이 각 영역에서 가장 큰 값들만 추출되어 down sampling 되었음을 알 수 있다. 이러한 pooling layer에서는 convolution layer와 다르게 파라미터와 padding이 존재하지 않는다.
5. Conv layer에서의 Hyperparameter
convolutional layer에는 4가지 하이퍼 파라미터가 있다.
1) 필터의 개수
2) 필터의 크기
3) stride
4) zero padding
➰ Parameter Sharing
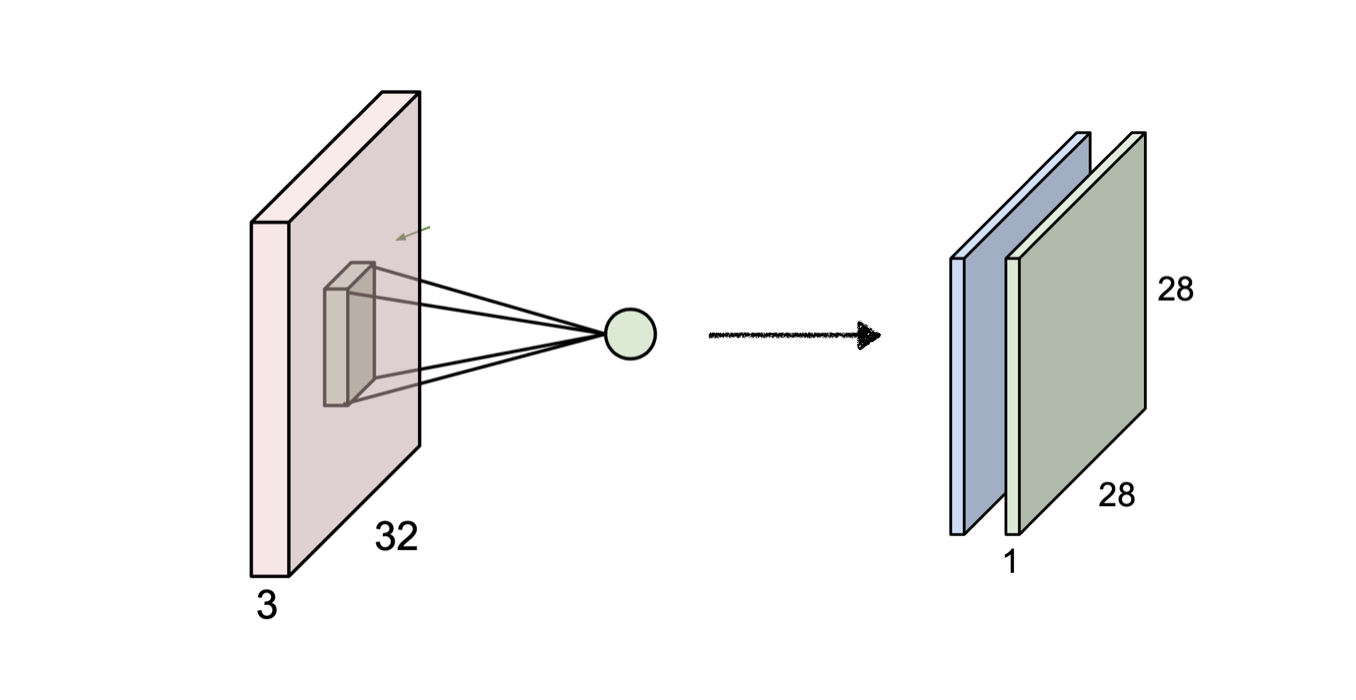
동일한 depth내의 뉴런들을 동일한 weight를 가지며 이것을 parameter sharing이라 한다. 따라서 위의 그림에서 파란색 필터를 적용해서 나온 파란색 activation map내에서는 paramter sharing을 하고 있는 것이다. 같은 원리로 초록색 activation map 또한 내부적으로 같은 parameter를 적용한 것이다.
➰
반면 별개의 activation map에 속하면서 동일한 위치에 있는 뉴런들의 경우는 각각 다른 weight 가진다(즉, parameter sharing을 하지 않는다)
🖇참고 문헌
https://www.youtube.com/watch?v=rdTCxAM1I0I&list=PL1Kb3QTCLIVtyOuMgyVgT-OeW0PYXl3j5&index=6



