
이전 게시물에서는 한 개의 독립변수(X)와 한 개의 종속변수(Y)에 대해 다뤘다. 이번에는 여러 개의 독립변수와 한 개의 종속변수를 이용하여 조금 더 복잡한 수식을 만들어내는 모델을 만들어보도록 한다.
🖇 이전 게시물 확인 : [〚딥러닝〛] - 딥러닝 기초 (생활코딩 정리1) - 텐서플로우(Tensorflow)를 이용한 레모네이드 판매 예측
📌 데이터 파악
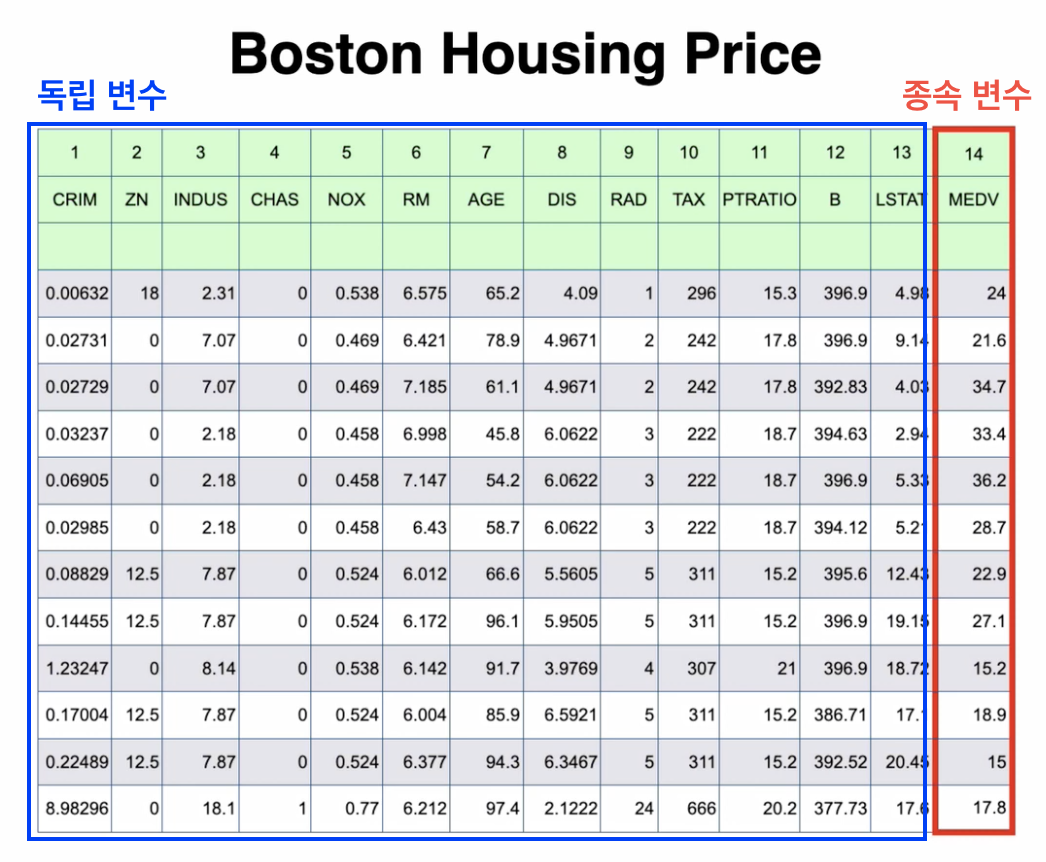
이번 실습에 사용할 데이터는 보스턴 집값 데이터로, 13개의 독립변수와 1개의 종속변수로 구성되어 있다.
📌 데이터 준비
보스턴 = pd.read_csv('boston.csv')
독립 = 보스턴[['cirm','zn','indus','chas','nox','rm','age','dis','rad','tax','ptratio','b','lstat']]
종속 = 보스턴[['medv']]
print(독립.shape, 종속.shape)pd.read_csv를 이용하여 해당 데이터를 불러온 다음, 13개의 columns를 독립변수로, 1개의 columns를 종속변수로 분리한다.
📌 모델 구조 형성 : 퍼셉트론, 가중치, 편향
➰ 독립변수 = 13개 & 종속변수= 1개인 경우
X = tf.keras.layers.Input(shape=[13])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X,Y)
model.compile(loss='mse')현재 데이터에서 독립변수의 개수가 13개이므로 shape=[13]으로 적어주고, 종속변수는 1개이므로 Dense(1)로 작성해준다.
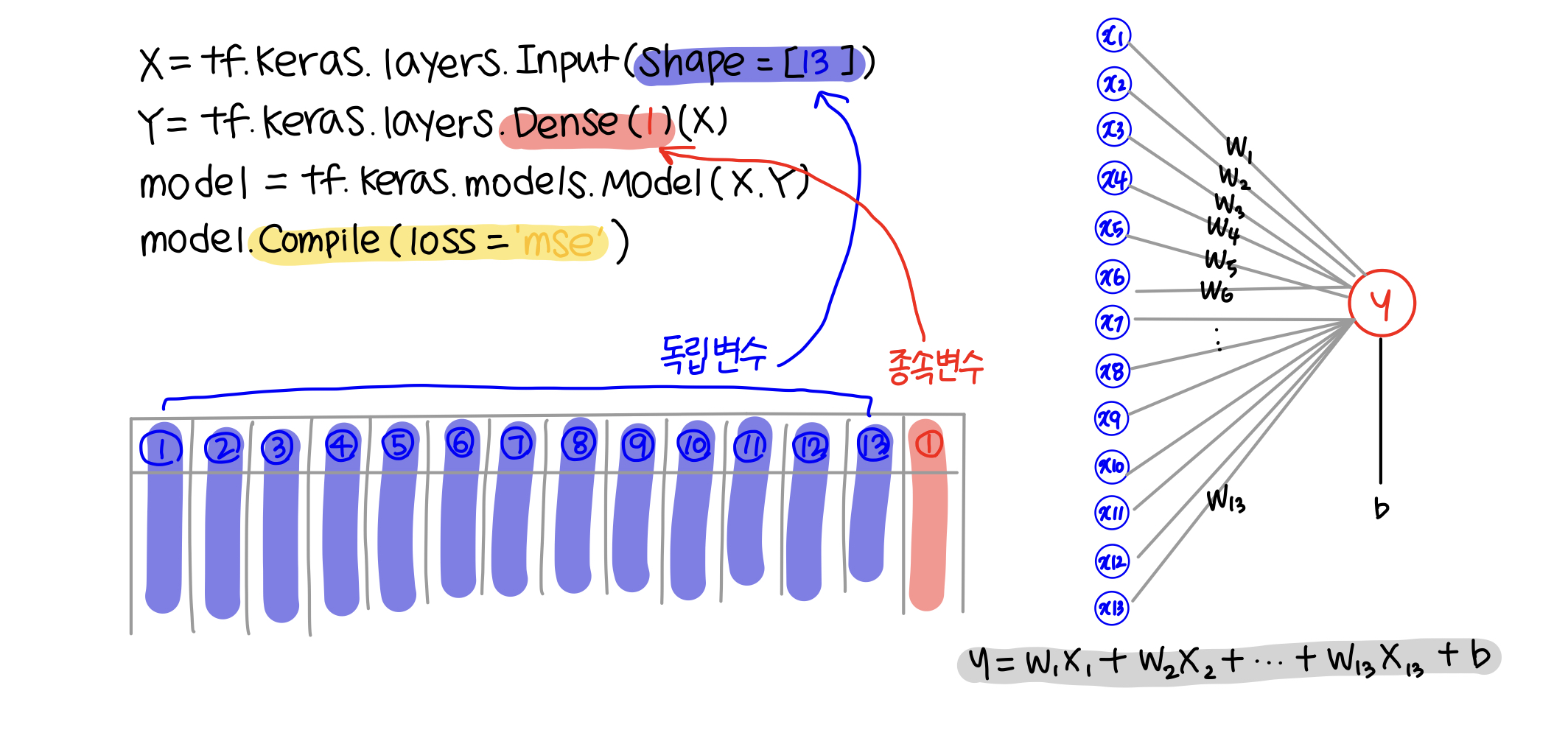
위의 코드를 그림으로 표현할 수 있는데, 먼저 독립변수가 13개이므로, shape에 13을 적어주었다. 이는 13개의 입력을 받는 입력층을 구성한다고 볼 수 있다. 종속변수는 1개이기 때문에 코드 두 번째 줄의 Dense layer에는 1을 적어주었다. 따라서 이를 그림으로 표현하면 1개의 출력층을 구성한다고 볼 수 있다. 조금 더 정확하게 표현하면 두 번째 코드는 13개의 입력을 받아 1개의 출력을 만들어내는 구조를 만든다 1개의 출력을 만드는 구조를 수식으로 표현하면 Y = W1X1 + W2X2 +... + W13X13 + b로 표현한다. 컴퓨터는 학습과정에서 입력되는 데이터를 보고 이 수식의 W와 b를 찾는다.
우리가 만든 이 모델은 1개의 뉴런으로 이루어져 있다. 뉴런은 실제 두뇌 세포의 이름인데, 인공 신경망에서 뉴런의 역할을 하는 것이 우리가 위에서 만든 수식인 것이다. 또한 이 수식을 '퍼셉트론(perceptron)'이라고 한다. 수식에서 W는 '가중치(Weight)'라고 하며, b는 '편향(bias)'라고 한다.
➰ 독립변수 = 12개 & 종속변수 = 2개인 경우
X = tf.keras.layers.Input(shape=[12])
Y = tf.keras.layers.Dense(2)(X)
model = tf.keras.models.Model(X,Y)
model.compile(loss='mse')

이번에는 독립변수가 12개, 종속변수가 2개라고 가정하고 모델을 만들어보자. 이러한 경우 Input layer의 수는 12, Dense layer의 수는 2로 설정한다. 하나의 결과를 만드는 데에는 1개의 수식이 필요한데, 현재 종속변수가 2개이므로 2개의 수식이 필요하다. 따라서 이러한 경우 퍼셉트론 2개가 병렬로 연결된 구조가 형성되며, 컴퓨터가 찾아야 하는 가중치의 개수는 첫 번째와 두 번째 수식에서 각 12개의 W와 1개의 b로 즉, 26개를 찾아야 한다.
📌 실습 : 보스턴 집 값 예측
# 라이브러리 사용
import tensorflow as tf
import pandas as pd
###########################
# 1.과거의 데이터를 준비합니다.
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv'
보스턴 = pd.read_csv(파일경로)
print(보스턴.columns)
보스턴.head()
# 독립변수, 종속변수 분리
독립 = 보스턴[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat']]
종속 = 보스턴[['medv']]
print(독립.shape, 종속.shape)
###########################
# 2. 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[13])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
###########################
# 3.데이터로 모델을 학습(FIT)합니다.
model.fit(독립, 종속, epochs=1000, verbose=0)
model.fit(독립, 종속, epochs=10)
###########################
# 4. 모델을 이용합니다
print(model.predict(독립[0:5]))
# 종속변수 확인
print(종속[0:5])
###########################
# 모델의 수식 확인
print(model.get_weights())4) 모델 이용하는 코드는 얼마나 정답을 정확하게 예측하고 있는지 확인하는 단계이다. 이때 독립변수 전체를 넣으면 너무 많으므로 0번째부터 5개의 데이터만 넣어 확인해보도록 한다. model.predict(독립[0:5]) 이때, 파이썬 문법 중 슬라이싱이라는 개념이 사용되는데 그 개념에 대해 다시 알고 싶다면 bigdaheta.tistory.com/7?category=958415 본문 4번 내용을 확인!
참고 사이트



