
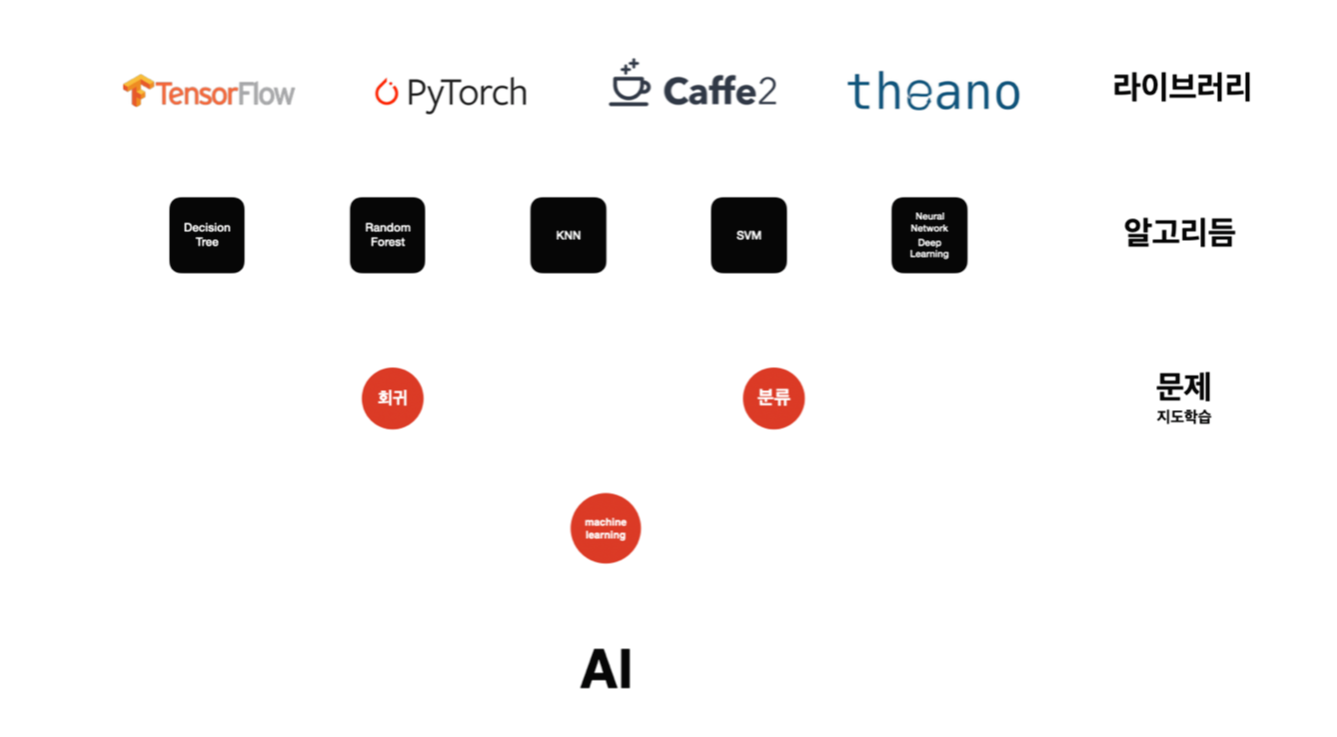
📌 라이브러리에서 AI까지 이어지는 계층 구조
📌 지도 학습 과정
1) 과거의 데이터 준비하기
2) 모델의 구조 만들기
3) 데이터로 모델 학습(fit)시키기
4) 모델을 이용하여 값을 예측하기
➰ 과거의 데이터 준비
레모네이드 = pd.read_csv('lemonade.csv')
독립 = 레모네이드[['온도']]
종속 = 레모네이드[['판매량']]
➰ 모델의 구조 만들기
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X,Y)
model.compile(loss='mse')
➰ 데이터로 모델 학습(fit)시키기
model.fit(독립, 종속, epochs=1000)
➰ 모델을 이용하여 값 예측
print("Predictions: ",model.predict([[15]]))
📌 loss의 의미

이번 학습이 몇 번째 학습인지 알려주는 부분
각 학습마다 얼마나 시간이 걸렸는지 알려주는 부분
학습이 얼마나 진행되었는지 알려주는 부분. 각 학습이 끝날 때마다 그 시점에 모델이 얼마나 정답과 가까운지 평가하는 지표

먼저 독립변수(X)와 종속변수(Y)를 준비하여 모델을 만든다. 그 후, 독립변수를 모델에 넣어주면 모델은 그에 따른 예측결과를 만들어낸다.

우리가 만든 모델이 얼마나 좋은지 평가하기위해, 준비한 실제 정답인 종속변수와 모델에 의해 나온 예측 결과를 비교한다.

모든 예측과 실제 결과를 비교하여 그 차이를 구한다.(예측-실제 결과) 각 차이의 제곱을 한 결과들의 평균을 구하고 그 값을 'loss'라고 한다.
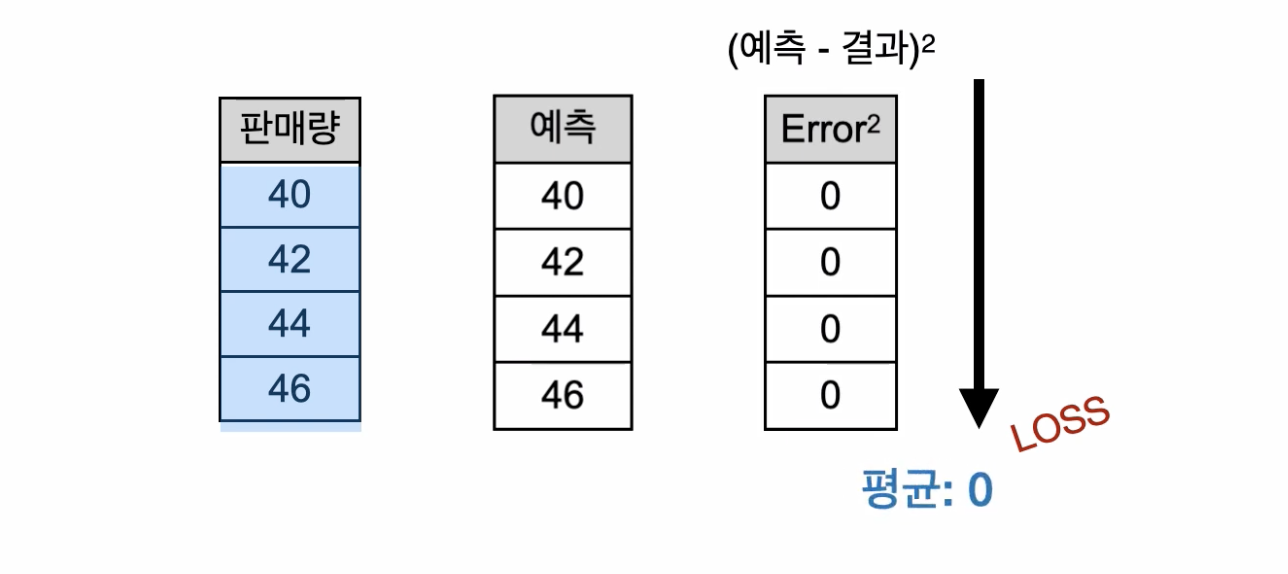
만약 우리가 만든 모델이 실제 결과를 완벽히 예측했다면 예측값과 실제 값의 차이는 0이 될것이다.(즉 loss가 0) 따라서 loss가 0에 가까울수록 학습이 잘 되었다고 보면 된다. 때문에 우리는 학습을 시킬 때 loss값을 보면서 epoch마다 loss가 0에 가까워지고 있는지 확인하는 것이 중요하다.(loss가 떨어지고 있으면 학습이 되고 있다는 의미이다.) loss가 원하는 수준으로 떨어질때 까지 반복해서 학습을 시키면 된다.
📌 실습 : 레모네이드 판매 예측
➰ 라이브러리 사용
import tensorflow as tf
import pandas as pd
➰ 데이터 준비
raw.githubusercontent.com/blackdew/tensorflow1/master/csv/lemonade.csv
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/lemonade.csv'
데이터 = pd.read_csv(파일경로)
데이터.head()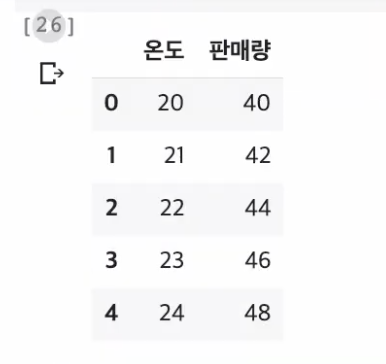
➰ 독립변수 & 종속변수 분리
독립 = 데이터[['온도']]
종속 = 데이터[['판매량']]
print(독립.shape, 종속.shape)
➰ 모델 만들기
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')shape =[1] : 독립변수의 개수
Dense (1) : 종속변수의 개수
compile : 모델이 학습할 방법
➰ 모델 학습시키기
model.fit(독립, 종속, epoch=10)독립변수와 종속변수를 넣어주고 학습시킬 수(epoch) = 10으로 설정한 뒤 학습시킨다(fit)

10번 학습 시켰을때의 loss = 3498.2590 (굉장히 높은 편)
즉 우리가 만든 모델이 실제 정답을 맞히기에는 매우 부족한 모델이라는 의미이다.
( loss값이 0에 가까워져야 정답을 잘 맞힌다는 의미, 때문에 loss값은 '모델이 얼마나안 좋냐'라고 보면 된다.)
loss 값을 낮추기 위해 학습 횟수를 늘려보자.

학습을 10번 더 시켰을 때 loss값은 약 3466으로 이전보다는 loss값이 감소했다. 하지만 이 정도로는 모델이 실제 값을 정확하게 예측하기에 부족하므로 학습량을 더 많이 늘려보자.
model.fit(독립, 종속, epoch = 10000, verbose=0)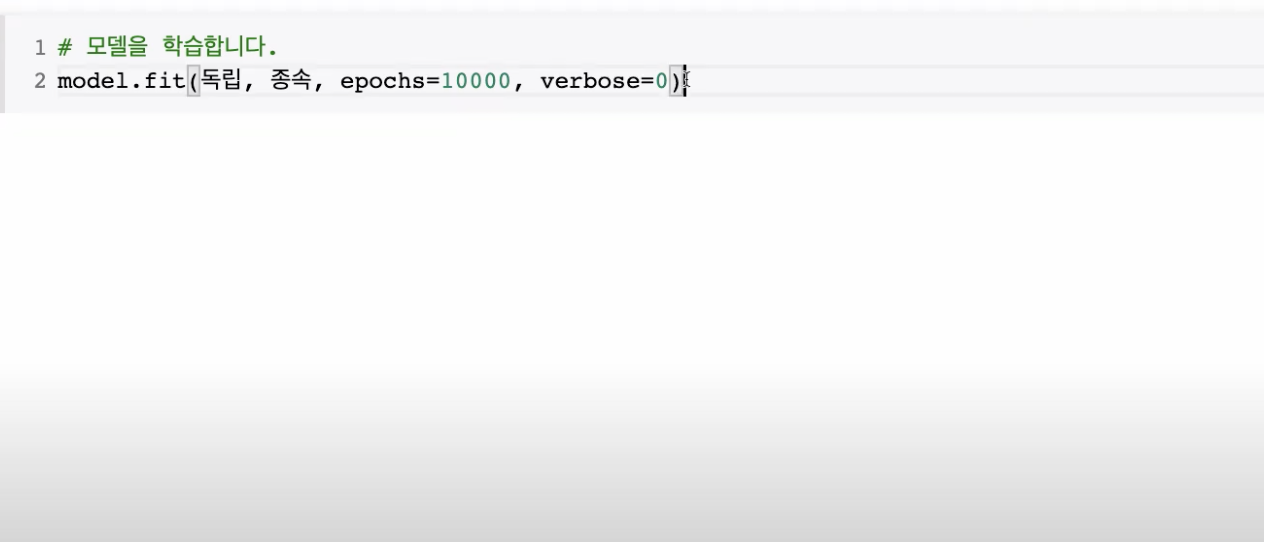
이번에는 epoch를 10000으로 설정하고 verbose = 0으로 하여 모델이 학습하는 동안 화면 출력을 하지 않게 설정한다.

학습의 결과를 다시 확인해보면 loss값이 2.2406e-04로 떨어졌다.
(e-04는 10의-4승(= 0.0001)이라는 의미로, 2.2406에 0.0001을 곱해주면 된다.)
따라서 최종 loss 값은 0.0002
loss값이 0에 가까워졌으므로 모델이 실제 값을 잘 예측한다고 볼 수 있다.
➰ 모델 이용하기
model.predict(독립)완성된 모델에 우리가 준비한 독립변수를 넣어서 종속변수를 잘 맞추는지 확인해보자.

모델에 의한 예측값과 실제 값을 비교해보면 어느 정도 비슷하게 값을 맞추고 있음을 알 수 있다.
model.predict([[15]])

이제 완성된 모델을 이용해보자. 내일 온도가 15도라면 몇 개의 레모네이드를 준비해야 될까? predict에 15를 적고 값을 출력해보면 30이라는 값이 출력된다. 즉 30개의 레모네이드를 준비하면 되는 것이다.
참고 사이트



