
1. 회귀(regression)란?

회귀(regression)는 여러 개의 x와 한 개의 y사이의 관계를 하나의 수식으로 나타내는 기법이다. 예를 들어, '집의 가격'은 지역, 역세권, 학군, 집의 크기 등의 여러 가지 요소로의해 결정될 수 있다. 이때 집의 가격은 y, 그 집의 가격에 영향을 줄 수 있는 여러 가지 요소들은 x로 설정하고 각 x요소들에 따라 집값이 어떻게 변하는지를 하나의 수식으로 나타내는 것을 '모델링'이라고 한다. 이처럼 x와 y를 하나의 식으로 나타내면 이 수식을 활용하여 여러 가지 문제들을 해결할 수 있게 된다.
예를 들어, x에 1이 들어왔을 때 y로 3이 출력되고, 2가 들어왔을 때 5가, 3이 들어왔을 때 7이 출력되는 하나의 함수가 있을 때, 이를 f(x) = 2x + 1으로 표현할 수 있다. 이때 x에 새로운 값인 4가 들어왔을때 그에 해당하는 y값인 9를 출력하게 된다.

| 영향을 주는 변수(x) | 독립변수(Independent Variable), 설명변수(Explanatory Variable), 예측변수(Predictor Variable) |
| 영향을 받는 변수(y) | 종속변수(Dependent Variable), 반응변수(Response Variable), 결과변수(Outcome Variable) |
2. 회귀 모델 이해
회귀분석은 지도 학습(supervised learning)의 기법 중 하나이기 때문에 '정답지(목표변수= y)'가 존재한다. 즉, 과거에 어떤 요소들에 의해 어떤 결과가 일어나는 것이 무수히 많이 반복되었을 때, 그 데이터들을 바탕으로 우리는 하나의 판단 지표가 생기게 된다(모델링). 이때 새로운 요소가 들어왔을 때 그에 따른 결과를 예측할 수 있게 되는 것이 지도 학습의 원리이다. 지도 학습에는 크게 분류와 회귀가 있으며, 목표 변수(결과변수)가 범주형인 경우에는 분류를, 연속형인 경우에는 회귀를 사용하게 된다. 다시 말해, 회귀분석은 내가 예측하고자 하는 값(y)이 연속형(숫자 형태)인 경우에 사용하는 기법이다. 예를 들어 집 값, 주가, 매출액 등 숫자 형태의 무언가를 예측할 때 회귀분석을 사용하면 되며, 이번 게시물에서는 회귀분석을 중점적으로 정리하고자 한다.


우리가 기존에 가지고 있는 데이터인 x = {1,2,3}, y={3,5,7}을 좌표평면에 표시하고, 이 점들을 이어 하나의 직선(y = 2x +1)을 만든다. 이 직선(y = 2x + 1)은 우리의 목표지점이라고 생각하면 된다. 현재는 데이터의 수가 적기 때문에 하나하나 계산할 수 있었지만, 데이터의 수가 엄청나게 방대해지면 인간의 힘으로는 식을 만들어내기 힘들어진다. 때문에 이 작업을 컴퓨터가 대신하게 만들어주자. 그렇다면 컴퓨터는 이러한 함수 식을 어떻게 도출할 수 있을까?

컴퓨터가 아직 최적의 직선을 찾지 못했다고 가정하고, 하나의 가설로 함수(y= ax + b)를 만들어보자. 이때 a는 직선의 기울기이며, 이를 회귀계수라고 표현한다. b는 절편이다. 우리가 해야 할 것은 최적의 a와 b를 찾는 것이다. 그 과정 첫 번째는 a와 b에 임의의 수를 넣어보는 것이다.
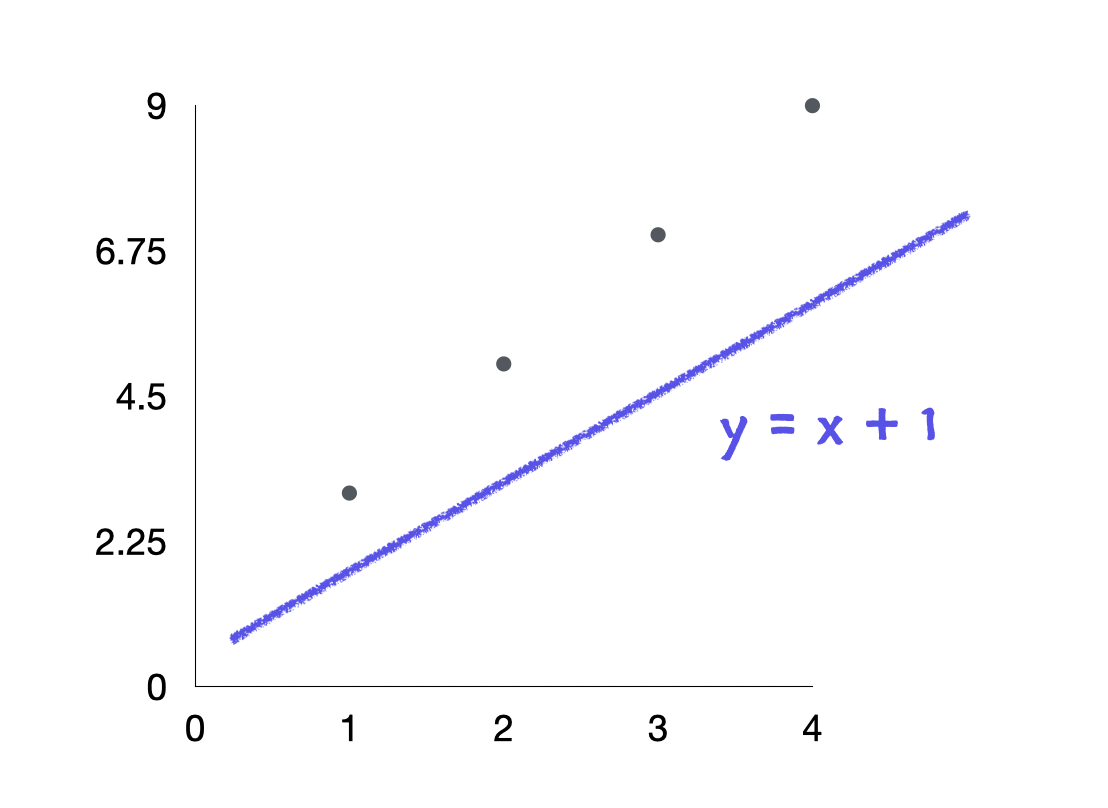
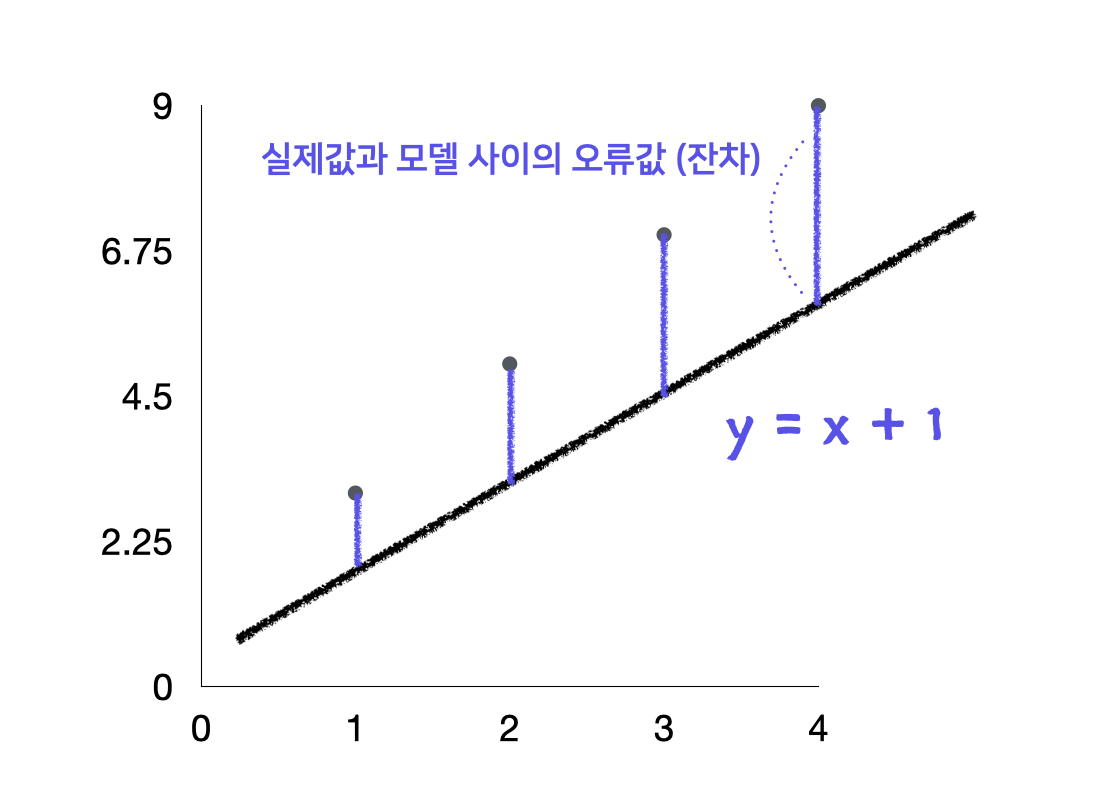
a=1, b=1을 대입하여 하나의 새로운 직선을 만들었다. 그다음 각 점(데이터)들과 직선(y= x + 1) 사이의 거리를 긋는다. 이때 실제 값들과 내가 그은 직선(모델) 사이의 거리를 '잔차'라고 한다.
3. 최소제곱법(Least square method)과 비용 함수(cost function)


비용 함수(cost function)는 '내가 임의로 지정한 a와 b의 값이 얼마나 잘못되었는지 알려주는 척도'라고 생각하면 된다. 위에서 설명했듯, 회귀분석은 지도 학습의 기법이기 때문에 정답이 정해져 있다. 따라서 그 정답을 기준으로 내가 낸 답이 얼마나 틀린 것인지 알 수 있는 것이다. 우선 1) 실제 데이터들을 좌표평면상에 나타낸다. 2) 임의의 직선 하나를 긋는다. 3) 그 선을 한변으로 하는 정사각형을 만든다. 4) 그 정사각형들의 면적을 모두 더한 값이 비용 함수의 값이다.


이 비용 함수는 '최소제곱법'으로 구할 수 있다. 정사각형의 면적의 총합은 실제 데이터들을 대표할 수 있게 직선을 잘 그을수록 작아지고, 실제 데이터들에서 멀어질수록 커지게 된다. 따라서 정사각형의 총합이 크다는 것은 내가 임의로 설정한 a와 b가 많이 잘못되었다는 뜻이므로 이 총면적이 최대한 줄어드는 방향으로 선을 그어야 하며, 이를 '최소제곱법'이라고 한다. 이때 최소제곱법은 회귀식(y = ax +b)의 a와 b를 잘 찾는 것이 초점이지, x와 y를 찾는 게 아니라는 점을 주의해야 한다.
그렇다면 비용 함수의 비용(오류)을 최소화하는 최적의 a와 b을 어떻게 찾을 수 있을까? 즉, 언제 a와 b의 값이 가장 최소가 될까?

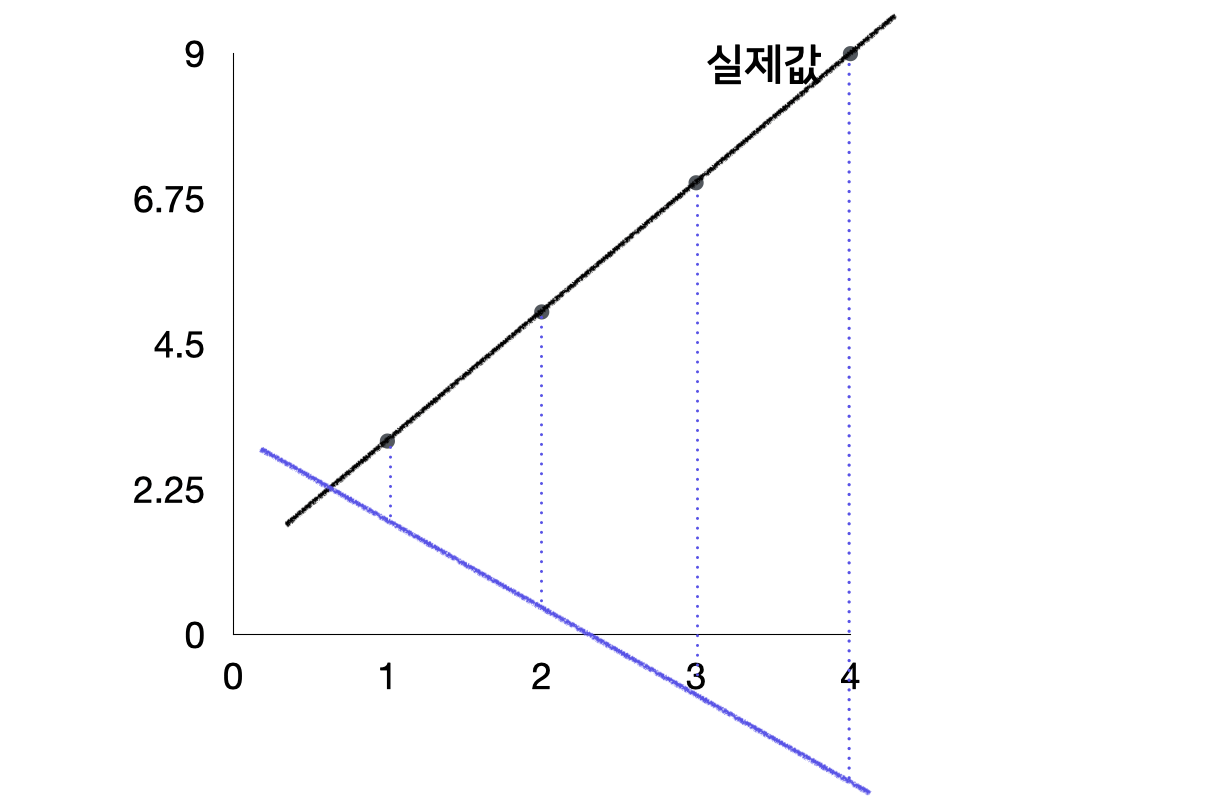
y = ax+ b에서 a는 직선의 기울기이므로 a가 변함에 따라 위의 그래프처럼 직선의 기울기가 변하게 된다. 또한 실제 값의 회귀선을 기준으로 a의 값을 줄일수록(혹은 늘릴수록) 점점 거리(잔차)가 증가한다. 이때의 비용 함수는 잔차에 제곱을 한 값이므로 (정사각형 넓이의 총합) 기울기가 조금만 달라져도 그에 따른 비용 함수의 값은 기하급수적으로 증가하게 된다. 즉 우리가 a와 b를 조금만 잘못 설정해도 비용함수의 값이 엄청 늘어난다는 것이다.
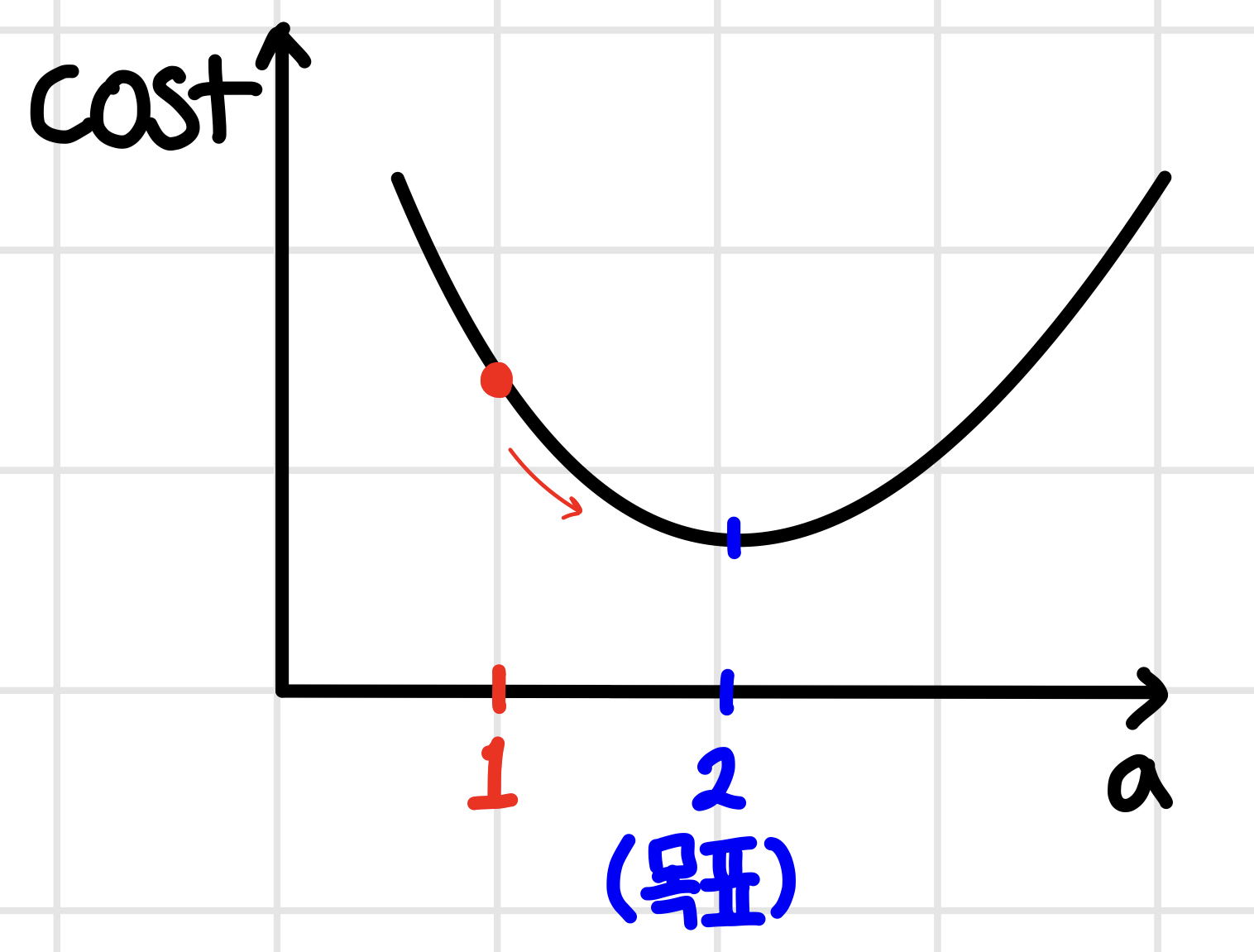
비용 함수는 위의 그래프처럼 2차 함수의 형태를 띠게 된다. 우리가 처음에 설정해놓은 회귀선 y = 2x + 1이기 때문에 a =2에서 convex 한 그래프가 형성되며, 이러한 형태의 그래프에서는 기울기가 '0'인 지점에서 최댓값 또는 최솟값을 가진다는 특징이 있다. 여기서 우리가 임의로 설정해본 y = x + 1에서 a = 1의 값을 가지므로, 위의 그래프처럼 빨간 점으로 표시할 수 있다. 그렇다면 빨간 점(임의의 a값)을 파란 점(실제값, 목푯값)이 있는 곳까지 어떻게 이동시킬 수 있을까?
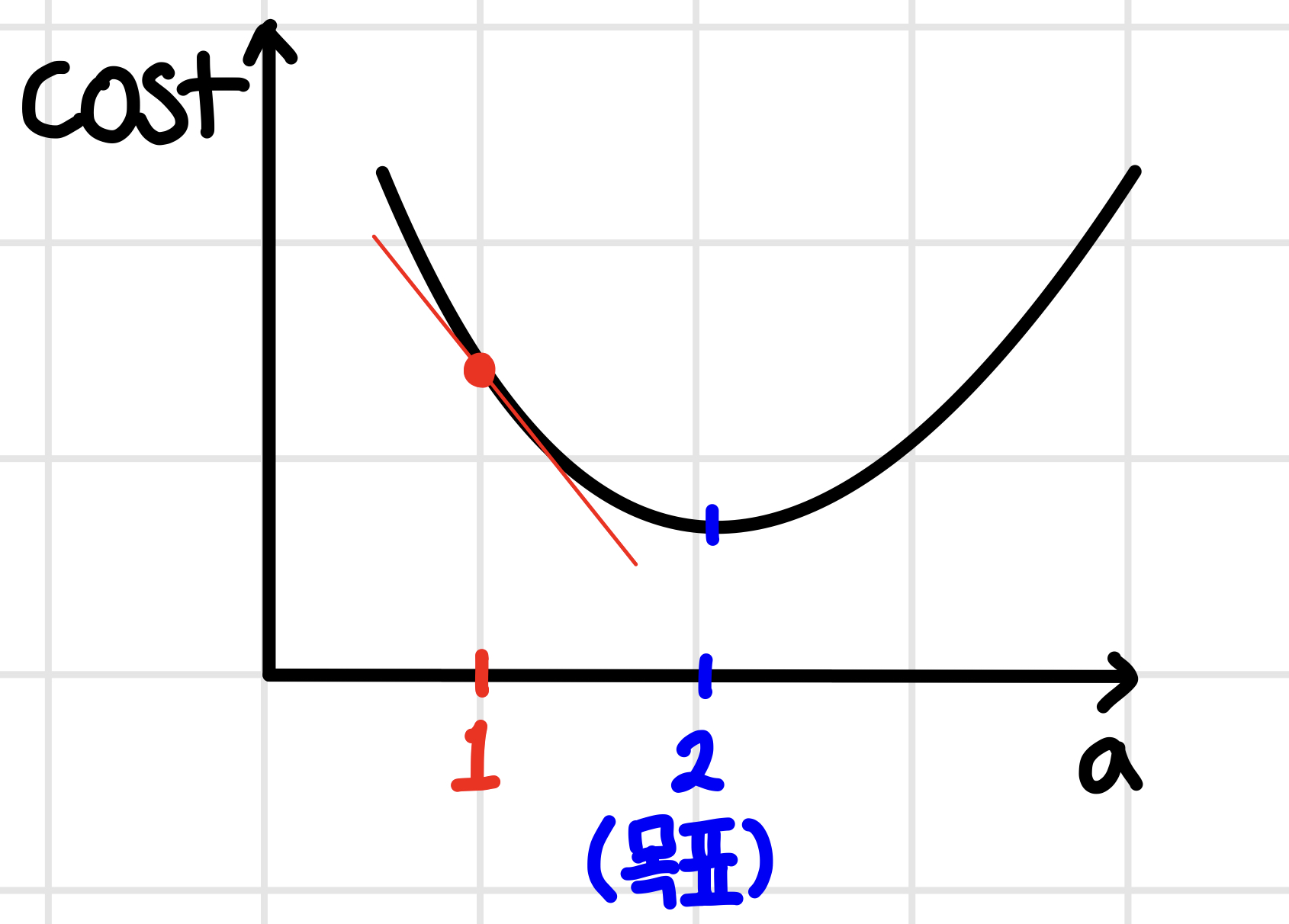

그 방법은 '기울기'를 이용하는 것이다. 우리가 임의로 설정한 a=1에서의 기울기는 음수이다. 여기서 한 가지 특징을 알 수 있는데, 현재의 위치에서 내가 목표로 하는 지점으로 가기 위해 미분을 해서 이차함수의 기울기를 구했을 때 현재 a처럼 기울기가 음수라면, '오른쪽'으로 가야 한다. 즉, a의 값을 증가시켜줘야 하고, a = 3일 때 기울기를 구해보면 양수이므로, 왼쪽으로 가야 한다. 즉 a의 값을 감소시켜주면 된다는 것이다.
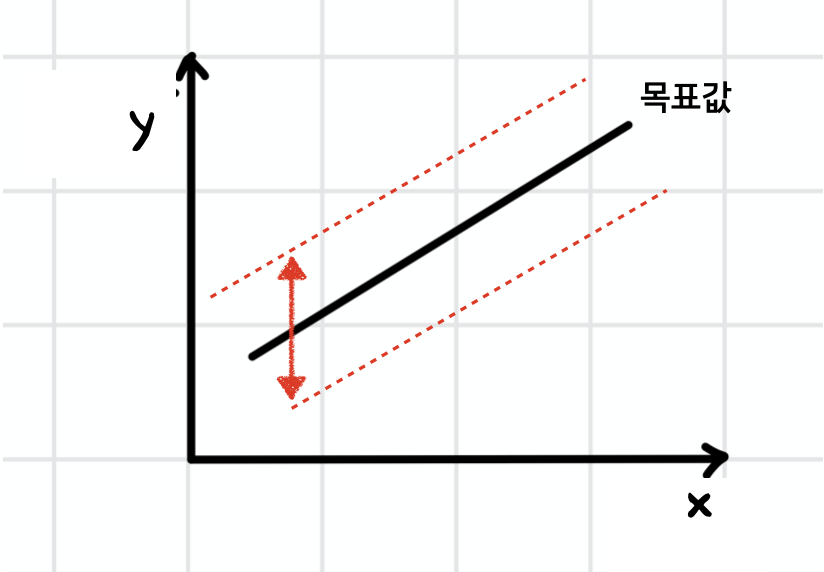

이번에는 기울기(a)는 고정된 상태에서 절편(b)의 값을 바꾸게 되면 선의 기울기는 고정된 상태에서 위, 아래로 이동하게 된다. b의 경우에도 마찬가지로 실제값과 내가 임의로 지정한 b의 값의 차이가 클수록 비용 함수의 값이 기하급수적으로 증가한다.
4. 경사 하강법(Gradient Descent)
위에서 설명한 원리를 이용하여 a와 b의 값을 계속 조정해주면서 우리가 목표로 설정해 놓은 값에 도달하게 만드는 것을 '경사 하강법(Gradient Descent)'라고 한다. 즉, 경사 하강법은 비용(cost)의 값을 줄이기 위해 반복적으로 기울기를 계산하며 변수(a와 b)의 값을 변경해나가는 과정이다. 따라서 비용 함수 식에서 a에 대한 기울기와 b의 기울기를 각각 구하고, 그것이 내가 목표로 한 값에 가까워질 때까지 계속해서 업데이트(수정)해주면서 최적의 a와 b를 찾으면 된다.


그럼 이러한 이론이 머신러닝에서는 어떻게 작동하는 것일까?

➰ Learning rate가 너무 작은 경우
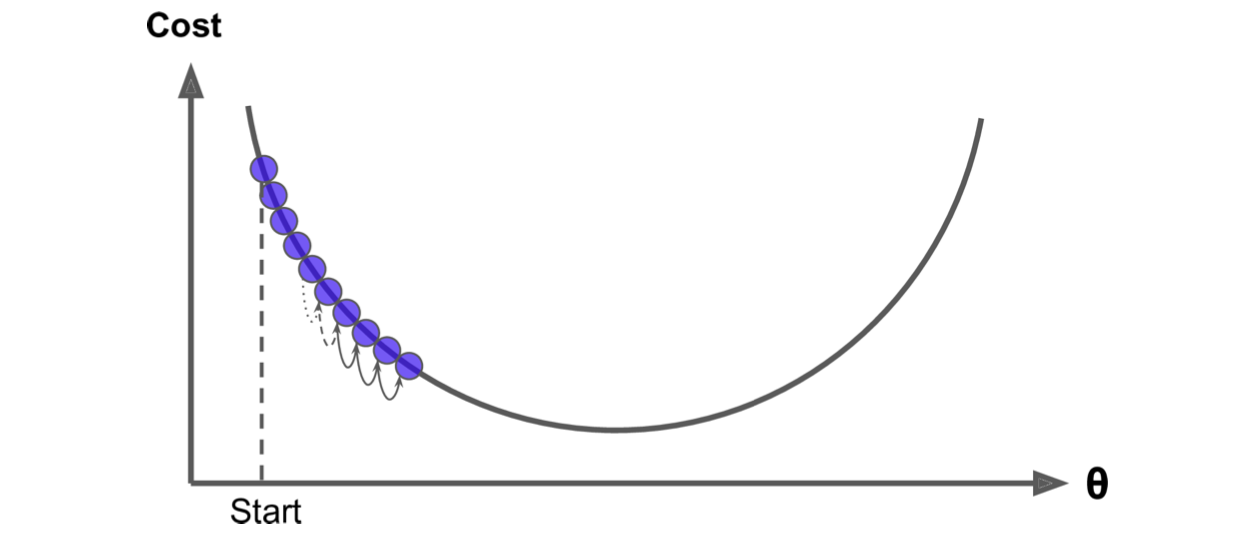
- 최저값까지 못 가고 멈춘다.
- 너무 조금씩 내려가므로 시간이 오래 걸린다.
(즉, 매우 느리게 학습하게 되어 최적화에 많은 시간이 걸릴 수 있음)
➰ Learning rate가 너무 큰 경우
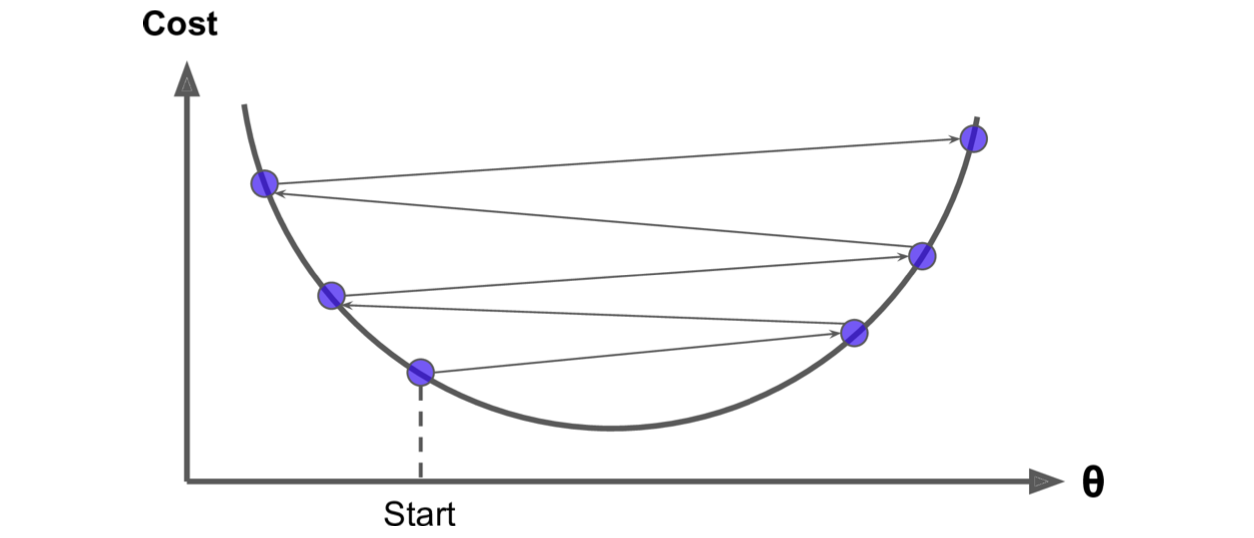
- 데이터가 튀는 문제가 발생한다.
- 최저값이 수렴하지 못하는 경우가 발생한다.
(기울기가 0인 지점을 지나치게 되어 최적화가 되지 못함)
📌 선형 회귀모델에서의 경사 하강법 요약
1) a, b를 임의의 값으로 초기화(설정)한다.
2) Cost function J(a, b)가 최소화될 때까지 학습을 진행한다.
3) 더 이상 Cost function이 줄어들지 않거나 학습 횟수를 초과할 때 종료시킨다.
5. 회귀 모형 검증
모델의 성능을 검증, 평가하는 것은 지도 학습인 경우에만 사용된다. 지도 학습인 경우에는 정답(결과변수)이 주어져있기 때문에 내가 만든 모형이 잘 만들어진것인지 아닌지 판단할 수 있기 때문이다. 지도학습에는 크게 분류와 회귀가 있는데, 분류는 결과변수가 범주/문자형인경우에 사용하고 회귀는 결과변수가 연속형/숫자형인 경우에 사용한다. 따라서 이에 따라 모델을 평가하는 지표가 달라지게 된다.
회귀 모델을 평가하는 대표적인 지표는 MSE(Mean Squred Error)와 R2(R-squre)이다.
MSE는 실제값과 예측값의 차이를 제곱한뒤, 평균을 낸것이다.이름에서도 알 수 있듯 어쨋든 error(오차)이기 때문에 MSE값은 작을수록 좋다.
R-squre(결졍계수)는 전체 데이터를 회귀 모형이 얼마나 잘 설명하고 있는지를 보여주는 지표로서, 회귀선의 정확도를 평가하므로 이 값이 1에 가까울수록 정확도가 높다는것이다.
▼ 머신러닝 회귀 이어서 보기 ▼
[머신러닝] 회귀(regression)-2 : 과적합(overfitting), 과소적합(underfitting), 편향 - 분산 트레이트 오프(Bi
1. 과적합(overfitting) 과적합(overfitting)이란, 모델이 학습 데이터에만 너무 잘 맞아서 새로운 데이터에 대한 예측력(일반화)이 떨어지는 것이다. 즉, 학습 데이터를 너무 과하게 학습해서 학습 데이
bigdaheta.tistory.com
참고 문헌 : youtu.be/ve6gtpZV83E,



