
1. Randomized Controlled Trial (RCT)
1-1. Randomized Controlled Trial (RCT)
- 연구자가 피험자를 무작위로 치료군(Intervention group)과 대조군(Control group)으로 배정하여, 특정 Intervention(약물, 치료 등)이 Clinical outcome에 미치는 영향을 평가하는 연구 설계 방법이다.
1-2. RCT의 장점
- 인과 관계 추론 가능 : 무작위 배정을 통해 교란 변수의 영향을 최소화하여, 노출(개입)이 outcome에 미치는 인과적 영향을 직접 평가 가능하다.
- 연구자가 조건을 직접 통제하기 때문에 인과관계를 보다 명확하게 확인할 수 있다.
2. Observational Study (관찰 연구)
2-1. 정의
- RCT가 윤리적이지 않거나, 실현 가능하지 않을때, 또는 치료가 환자에게 해롭거나 해당 치료를 원하지 않는 환자를 포함할 때 관찰연구를 진행하게 된다.
- 이미 일어난 치료나 노출 결과를 관찰하여 인과 관계를 추정하는 연구이다.
2-2. 특징
- 관찰 연구에서는, 연구자가 개입해서 실험 조건을 설정하거나 exposure(ex. 치료 방법, 약물)를 무작위로 할당하지 않는다.
- 대신 이미 존재하는 데이터를 바탕으로 결과를 분석하거나, 사람들이 자연스럽게 어떤 치료나 행동을 선택한 결과를 '관찰'하는 방식이다.
# wold의 정의
(만약, 실험 연구에서 해당 조건 중 하나라도 충족되지 않는 경우, 관찰연구로 간주)
조건 1) 실험의 반복이 동일한 조건에서 이루어져야 한다.
- 예) 온도, 시간, 실험 환경 등이 동일하게 유지되어야함
- 관찰 연구에서는 이러한 조건을 통제할 수 없기 때문에, 데이터가 각기 다른 조건에서 수집됨 (ex. 환자들의 나이, 건강상태, 기타 환경)
조건 2) 실험의 반복이 서로 독립적이어야 한다.
- 실험에서는 한 번의 실험이 다른 실험에 영향을 미치지 않아야 함 (독립성)
- 관찰연구에서는 데이터 간의 독립성을 보장하기 어려움.
조건 3) 무작위화
- 실험에서는 무작위화를 통해 통제되지 않은 요인(교란 요인) 이 치료군과 대조근에 균등하게 분포하도록 함.
- 관찰 연구에서는 연구자가 무작위화를 할 수 없기 때문에, 통제되지 않은 교란 요인들이 Outcome에 영향을 미칠 가능성이 높음.
*RCT vs Observational Study 비유
RCT
- 정확하게 레시피를 따라 해서 요리하는 것
- 동일한 재료, 양, 도구를 사용하여 반복적으로 요리하면 요리의 결과를 예측하기 쉬움
- 만약 요리의 맛이 다르게 나오거나 망쳤다면, 원인을 어느 정도 명확하게 파악하기 쉬움 (ex. 온도 문제 / 양 조절 문제 등)
Observational Study
- 여러 명이 각자 집에서 요리를 해서 가져와 결과를 비교하는 것
- 각자 사용한 재료, 도구, 요리 방식이 다르기 때문에 결과에 구체적으로 어떤 것이 영향을 미쳤는지 한 번에 파악하기 어려움
2-3. 관찰 연구에서 인과 추론(Causal Inference)을 어렵게 만드는 요인

실제 임상에서는 같은 적응증(indication)이라도 여러 가지 형태의 intervention(치료 또는 약물 등)을 적용할 수 있고, 그에 따라 Clinical outcome(증상 호전, 악화, 사망, 다른 질병 발생 등)이 달라질 수 있다.
예를 들어, 코로나 환자에게 A, B, C의 intervention을 적용할 수 있는 상황에서, 그중 한 환자에게 약물(A)을 적용했을 때 사망(Clinical Outcome)하는 상황이 발생했다고 가정해 보자.
'그렇다면, 만약 이 환자에게 B 또는 C약물을 적용했다면, 해당 환자의 Clinical Outcome이 달라졌을까?'
-> 이게 가장 중요한 질문!!! 결국 실제 임상에서 알고 싶은 것은 내 눈앞에 있는 환자에게 여러 가지 intervention 중에 과연 어떤 것을 선택해서 적용하는 게 최선일까? 가 궁금할 것이다.
하지만, 관찰 연구에서는
1) Counterfactual Outcome을 관찰할 수 없다.
(위의 예시에서 B 또는 C약물을 적용했을 때 혹은 아무런 intervention도 적용하지 않았을 때 해당 환자의 Clinical outcome을 'Counterfactual Outcome'이라고 한다.)
즉, 우리는 이 환자에게 A약물을 적용했을 때 현재 시점에 '사망'이라는 결과가 발생한것만 관찰할 수 있지, 과거로 다시 되돌아가서 B약물을 적용했을때 이 환자가 현재 시점에서 어떻게 결과가 달라지는지 관찰할 수 없다.
2) 보통, 치료가 무작위로 할당되지 않는다.(Treatment are typically not assigned at random in observational data)
- 의사의 선호도, 환자의 선호도 등 여러 가지 요인들로 인해 여러가지 치료들이 무작위로 할당되지 않는다.
- 'Random'하다, '양쪽 그룹이 동일하다'는 것은 결국 Exchangeable(교환이 가능하다)는 가정이 성립되는 것인데, 하지만 현실에서는 항상 랜덤 하게 두 그룹을 나눌 수 있는 것 아니다.
- 따라서 치료군과 대조군에서 기저 특성 차이가 발생될 수 있는데, 이러한 교란요인(counterfactual outcome)을 통제하지 않으면 치료 효과를 정확하게 추정하기 어려워진다.
- 즉, 두 집단의 기저 특성이 애초에 다르게 구성되어 있었다면, 해당 Clinical Outcome이 A치료의 효과로 발생된 것인지, 아니면 그냥 기저 특성의 차이 때문에 발생된것인지 명확하게 파악하기 어렵다.
3. Propensity Score
- 앞서, 관찰연구에서는 Intervention group과 control group이 랜덤 하게 배정된 것이 아니기 때문에, 각 그룹의 기저 특성의 차이가 발생될 수 있고, 이로 인해 제대로 인과추론을 하기 어렵다는 한계가 있었다. 이러한 한계점을 보완하기 위해 Propensity Score라는 개념이 나타나게 된다.
(-> 두 그룹의 기저 특성을 어느 정도 비슷하게 맞추기 위해 사용되는 개념.)
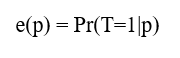
T : treatment assignment (치료 할당 변수)
P : a set of all covariates at the time of treatment assignment (치료 할당 시점의 모든 공변량의 집합)
3-1. 정의
- Propensity Score는 간단히 말해,'환자가 특정 치료를 받을 확률'을 의미한다.
- 치료 할당과 관련된 모든 공변량을 단일 확률값(스칼라 값)으로 요약한 값으로, 치료군과 대조군의 공변량의 분포를 유사하게 만들어 교란 요인을 조정하기 위해 사용한다.
- 두 집단의 각 특성(나이, 성별, 기저질환 등)들을 하나하나 비슷하게 맞추는 것은 어려울 텐데, 이때 Propensity score 개념을 적용하면, 수많은 공변량들을 하나의 스칼라값으로 만들어주기 때문에 이 값만 두 그룹 간 유사하게 만들면 되고 따라서 비교적 쉽게 두 집단의 특성을 비슷하게 맞출 수 있게 된다.
- 단, Outcome을 보지 않은 상태에서 분석이 이루어져야 한다.
* 공변량(Covariates)
- 연구에서 치료나 Outcome에 영향을 미칠 수 있는 변수들.
- 나이, 성별, BMI, 흡연 여부, 기저질환(Comorbidities), 약물(Medication), 진단 정보(Diagnosis) 등을 의미.
- 단, Propensity score는 관찰 가능한 공변량만 조정하며, **관찰되지 않은 Confounding factors(교란 요인)은 통제할 수 없음.
3-2. 적용 방법
1) PS Matching
- Intervention group과 Control group에서, Propensity score가 비슷한 환자를 1:1 또는 1:n으로 짝지어 비교하는 방법
- 치료군과 대조군을 직접 매칭하기 때문에 교란 요인을 줄이고, 결과 해석이 직관적
- 단, 매칭되지 않은 환자들은 분석에서 제외되기 때문에 표본의 크기가 줄어들 수 있음
- ex) 고혈압 환자들에서 A약물을 복용한 환자들(Intervention group)과 그렇지 않은 환자들(Control group) 중, 나이, 성별, 기저질환 등의 특성이 비슷한 환자를 매칭하여 비교
2) Stratification (층화)
- Propensity score를 기준으로 환자들을 여러 계층(strata)으로 나누어 분석
- 각 계층에서 치료군과 대조군의 공변량이 유사해지므로, 각 계층 내에서 비교가 용이
- 계층별 치료 효과를 분석한 뒤, 이를 합산하여 전체 효과를 추정
- 표본을 버리지 않고, 전체 데이터를 분석에 포함할 수 있음
- 계층의 수와 경계를 연구자가 직접 설정해야 하기 때문에 임의성과 어려움이 있을 수 있음
- ex) PS를 기준으로 5개의 그룹으로 분할하고, 각 그룹에서 약물 A 복용 여부에 따른 심혈관 사건 발생률 비교
3) Weighting (가중치)
- 환자별 Propensity socre에 기반으로 가중치를 부여해서 분석
- 치료군과 대조군의 특성을 전체 인구 수준에서 평균화하여 공변량 균형화
- 표본의 손실이 없고, 전체 인구의 평균적인 치료 효과(ATE)를 추정할 수 있음
- Propensity score가 극단적으로 높거나 낮은 경우, 가중치가 지나치게 커져 분석 결과가 불안정할 수 있음.
- ex) 약물 A가 심혈관 사건 예방에 미치는 전체 인구 수준의 효과는?
4) Regression Adjustment (회귀 분석 조정)
- Propensity score를 회귀 모델에 공변량으로 포함하여 결과 분석
- 치료 효과를 추정하면서, 공변량을 조정하여 결과에 미치는 영향 최소화
- 다양한 공변량을 동시에 조정 가능
- 모델의 적합성이 중요하며, 회귀 분석에 포함되지 않은 숨겨진 교란 요인은 여전히 문제가 될 수 있음
- ex) 회귀 분석에서, Outcome(심혈관 사건)을 PS와 치료 변수를 포함한 모델로 분석
4. Causal Inference
관찰연구에서 Intervention의 효과를 정확하게 분석하고, 공정하고 신뢰성 있는 인과 추론을 위해서는 다음과 같은 3가지 가정을 만족해야 한다.
1) SUTVA (Stable Unit Treatment Value Assumption)
- 치료를 받은 사람들끼리 서로 영향을 주면 안 됨.
- 즉, 약물 연구에서 한 사람이 약을 먹었다고 해서, 다른 사람의 Outcome이 달라지면 안 됨.
- 또한, 동일한 치료는 항상 동일한 방식으로 적용되어야 함.
2) Strong Ignorability (Unconfoundedness)
- 치료를 받을지 말지는 환자의 특성(X)에 의해 결정되지만, 치료와 결과 사이에는 직접적인 교란이 없어야 함.
- 즉, 해당 치료(or 약물)가 진짜 효과 있는지 분석하기 위해서는 해당 치료와 Clinical Outcome 사이에 Confounding factors(다른 교란 변수들)을 잘 통제해야 함.
- 가장 만족시키기 어려움.
3) Positivity (Overlap)
- 모든 환자들은 치료를 받을 확률과 받지 않을 확률이 모두 있어야 함 (즉, 어느 한쪽으로 너무 쏠려있으면 안 됨).
5. 관찰 연구에서 RCT를 모방하기 위한 주요 구성 요소 (Protocol Components to Emulate)
관찰 연구는 RCT와 달리, 치료가 무작위로 할당되지 않기 때문에, 잠재적 편향을 줄이고 연구 결과의 신뢰성을 높이기 위해 체계적이고 명확한 연구 설계가 필요한데, 이를 위해 RCT를 모방하는 아래의 구성 요소들을 따라야 한다.
1) Eligibility criteria (선정 기준)
- 연구에 포함될 대상자들의 조건 명확히 정의.
- 특정 나이 범위, 진단된 질병, 특정 기간 동안의 약물 사용 이력 등.
- ex) 20~65세 성인에서(특정 나이), 2형 당뇨병 진단을 받은(진단된 질병), 지난 6개월 동안 특정 약물 A를 복용한 기록이 있는 환자 (약물 사용 이력).
2) Treatment strategies (치료 전략)
- 연구 대상자들에게 적용된 치료 방법 또는 전략을 구체적으로 기술.
- 치료군과 대조군에서 각각 어떤 치료를 받을지 정확하게 정의.
- 특정 약물 요법, 비약물적 치료 등.
- ex) 약물A를 복용한 그룹과 약물 B를 복용한 그룹을 비교.
3) Assignment procedures (할당 절차)
- 치료나 비교군으로의 할당되는 방식 기술.
- 관찰 연구에서는 치료 할당이 무작위가 아니므로, 할당 과정의 잠재적 편향을 설명해야 함.
- ex) 의사 처방에 따라 A약물이 선택되었다.
4) Follow-up period (추적 관찰 기간)
- 대상자들을 관찰하여 Outcome을 측정하는 시간(기간)을 정의.
- ex) 치료 시작 후 6개월 동안 심혈관 사건의 발생 여부 관찰.
5) Outcome(결과)
- 연구에서 측정하고자 하는 주요 결과 정의.
- 사망률, 질병 악화, 입원율, 병원 재방문 등.
- 약물 A가 심혈관 사건 발생률(Outcome)을 줄이는가?
6) Causal contrasts of interest (인과 대조)
- 연구에서 비교하고자 하는 두 치료 간의 인과 관계를 명확히 정의.
- 약물 A와 약물 B 효과 비교.
- ex) 약물 A가 약물 B보다 사망률을 더 줄이는가?
7) Analysis plan(분석 계획)
- 데이터를 분석하는 방법과 절차를 사전에 계획
- ex) Propensity score를 이용해 두 그룹을 비교하고, 다변량 분석으로 교란요인을 조정한다.
6. 약물 역학 연구에서 Propensity Score를 사용하는 이유
1) Confounding by Indication (적응증에 의한 교란) 해결
- 보통, 약물은 환자의 적응증(indication)에 따라 처방됨
- 따라서 질병의 상태가 더 심각한 환자가 특정 약물을 처방받을 가능성이 높다면, 약물 효과가 질병 중증도 간의 교란이 발생할 수 있음
- 이러한 적응증에 의한 교란은 결과 해석을 왜곡할 수 있음
- 이때 Propensity score를 사용하면 약물 사용 여부에 영향을 미치는 공변량 (병력, 기저질환, 연령 등)을 조정하여 적응증에 의한 교란을 줄일 수 있음
-ex) 심혈관 질환이 높은 환자들이 더 자주 A약물을 처방받는다고 가정했을 때, Propensity score를 적용하면 이러한 위험 요인을 통제한 상태에서 약물 A의 효과를 분석할 수 있음.
2) 인구의 균형화 (Matching or Trimming the population)
- Propensity score는 치료군과 대조군 간의 공변량 분포를 비슷하게 만들어, 유사한 환자들끼리만 비교할 수 있게 함.
- 따라서 적합하지 않은 환자들은 제외되므로 비교를 용이하게 만듦
3) Outcome 발생이 적을 때에도 효과적인 추정
- Clinical Outcome이 드물게 발생하는 연구에서, 공변량이 많으면 통계적 분석이 어려워질 수 있음
- Propensity score는 여러 공변량을 단일 점수로 요약해서 분석하므로, 이러한 경우에도 신뢰성 있는 분석이 가능해짐.
4) 환자 수준의 반응 이질성(Heterogeneity in Response) 탐구
- PS를 통해 치료군 내에서 환자 개개인의 특성에 따라 치료 효과가 어떻게 달라지는지 알 수 있음.
- 이를 통해 환자 맞춤형 치료 전략을 설계하거나, 특정 환자군에서 치료의 유효성을 평가할 수 있음.
- ex) 약물 A가 20대보다 60 이상 고령 환자들에서 더 효과가 좋은지 확인 가능.
5) 측정 오류 보정 (Calibration for Measurement Error)
- 약물 사용 데이터는 불완전하거나 정확하지 않을 수 있음 (처방 기록 누락 등)
- PS는 이러한 데이터의 불완전성을 보정하여 측정 오류로 인한 편향을 줄이는 데 사용할 수 있음
- ex) 환자의 약물 복용 기간이 불명확한 경우, PS를 통해 약물 사용 여부와 효과를 더 정확하게 추정 가능.
7. New-user cohort design
7-1) 정의
- 연구 시작 시점부터 치료를 처음 시작한 환자들만을 대상으로 치료 효과를 분석하는 설계 방법
- 이때,'New-User'라는 것은 그 어떤 약물 복용 경험이 없는 환자들을 의미하는 게 아니라, 내가 해당 연구에서 적용하고 싶은 약물(A)의 복용 이력이 없는 환자를 의미.
- 보통 washout period를 1년으로 설정하여, 약물(A) 복용 시작 시점 이전에 1년 동안 해당 약물을 복용한 경험이 없는 환자들을 포함
- 기존에 해당 약물을 계속 복용 중이었던 환자와 지금 막 약물을 복용하기 시작하는 환자들을 비교하면 편향이 발생할 수 있기 때문에 이를 제거하기 위해 New User만으로 구성된 코호트 설계 필요
- 특히, Immortal Time Bias를 제거하기 위해 New-user cohort design을 적용
7-2) Immortal Time Bias
- 연구에서 결과가 발생할 수 없는 기간인데, 이 기간을 '치료받은 시간'으로 잘못 포함시키는 것을 의미함.
- 즉, 치료 시작 시점을 명확하게 정의하지 않거나, 치료 이전 기간을 분석에 포함시킬 때 발생되는 bias.
- 이 기간 동안 사망이나 질병과 같은 Outcome이 발생하지 않기 때문에 치료 효과가 실제보다 더 좋아 보임.
- 결과적으로 해당 Intervention이 엄청난 효과가 있는 것처럼 착각하게 만듦!
ex) 암 치료제(B)가 환자의 생존율을 높이는지 평가
'치료제 B를 처방받은 환자들(Intervention group)과 처방받지 않은 환자들(Control group)의 생존율 비교'
-> 이때, Intervention group의 일부는 암 진단 후 2개월 뒤에 치료제 B를 처방받음
-> 연구자는 치료제 B를 처방받기 전 2개월을 '치료받은 시간'으로 포함시켰음
- 이 2개월 동안 환자는 이미 생존해 있었기 때문에(생존해 있어서 처방까지 받을 수 있었음) 해당 치료제 B의 효과가 실제보다 훨씬 더 좋아 보이는 Bias가 발생됨
-> 결론적으로, 치료제 B를 복용하면 암 환자의 생존율을 높인 것처럼 보이지만, 이는 치료 시작 전의 immortal time bias일 수 있음
-> 이러한 Bias를 줄이기 위해 New-user cohort design을 적용!!!!! 혹은, 약물 처방 날짜를 기준으로 추적 관찰을 시작하도록 연구를 설계하기!!



