
01. 변수

- 그 값이 무작위 시행 (random experiment)에 의해 결정되는 것
- 하나의 숫자를 무작위 시행의 각 결과에 할당(assign)하는 함수
- 표본공간에서 실수로의 함수
- 변수가 특정한 값을 취하는 것 = 하나의 사건
- 데이터 중, 공통의 측정 방법으로 얻은 같은 성질의 값
- 통계학에서 변수의 개수는 '차원'이라 표현되기도 함.
*서로 독립인 두 사건
P(A∩B)=P(A)P(B)
또는
P(A│B)=P(A)
* 독립인 두 변수
P(X=x, Y=y) = P(X=x)P(Y=y)
P(X=x|Y=y) = P(X=x)
02. 변수의 종류
변수의 종류에 따라 확률을 계산하는 방법이 다르기 때문에 이를 구분하는 것이 필요.
2-1. 이산 변수
: 셀 수 있는 변수 (finite variable / countably variable)
* 셀 수 있지만, 그 값이 무한한 경우에도 이산 변수 (ex. 코로나 확진자 수, 1년에 백화점에 방문한 사람들의 수)
2-2. 연속 변수
: 셀 수 없는 변수 (infinite variable / uncountable variable)
- 온도, 무게, 길이 등
03. 변수의 확률 분포
데이터 분석의 첫 단계는, 데이터가 어떻게 분포되어 있는지를 그래프 등으로 시각화해서 대략적인 데이터 경향을 파악하는 것이 필요.
변수는 확률 분포를 갖는데, 변수의 종류에 따라 어떤 확률 분포를 사용할지가 달라지게 됨.
확률 분포 : 가로축에 확률 변수를, 세로축에는 그 확률 변수의 '발생 가능성'을 표시한 분포
확률분포는 파라미터(모수)를 통해 형태가 결정됨. 즉, 파라미터를 알면 확률 분포의 형태를 알 수 있게 됨.
데이터 분석의 목적은 모집단의 특성(모수)을 알고자 하는 것임. 따라서 모집단을 '00라는 파라미터를 가진 **라는 확률 분포로'나타낼 수 있다면, 모집단의 성질을 알게 되는 것.
3-1. 확률 질량 함수 (PMF, Probability Mass Function)


- 이산 변수가 특정한 값을 취할 확률을 나타낼 때 사용되는 함수.
- 이산변수 X의 확률 질량함수의 값은 'X가 특정한 값을 취할 확률'을 의미함.
- 확률변수가 이산형인 경우, 세로축이 확률 그 자체를 나타냄.
- 이산확률 분포의 예 : 베르누이 분포, 이항분포
(Example)
변수 X : 두 개의 동전을 동시에 던질 때 나오는 앞면의 수
x ∈ {0,1,2}
Px(0) = 1/4,
Px(1) = 2/4
Px(2) = 1/4
해석)
Px(0) : 두개의 동전을 동시에 던질 때 나오는 앞면의 수가 '0' 즉, 앞면이 하나도 안 나올 확률 = 1/4
3-2. 확률 밀도 함수 (PDF, Probability Density Function)


- 연속변수의 경우, 변수 하나의 특정한 값을 가질 확률은 '0'으로 정의됨 (별로 중요하지 않음)
- 즉, P(X=x) = 0
- 따라서 연속형 확률 변수의 경우에는 일정한 범위를 설정하여 확률을 구하고, 그 확률을 계산하는 함수를 '확률밀도함수'라고 함.
- 즉, 변수가 특정 구간 사이의 값을 취할 확률 X ∈ [a, b] 즉, a≤X≤b일 확률이 중요
- 확률밀도함수의 세로축은 확률 그 자체의 값이 아니라, 상대적인 발생 가능성을 표현한 값.
- 따라서 확률 변수가 어떤 값에서 어떤 값까지의 범위에 들어갈 확률을 알고 싶다면, 확률 밀도 함수를 적분하여 x축과 확률밀도함수로 둘러싸인 부분의 넓이를 구해야 함.
- 즉, 이 넓이가 확률에 해당
- 확률변수 전체를 적분하면 1이 됨.
04. 정규확률분포(Normal Probatility Distribution)


- 'Bell curve' 또는 'Gaussian curve'라고도 불림.
- 2개의 파라미터로 확률 분포의 형태가 결정됨 (평균 μ , 표준편차 σ )
- 평균 μ을 중심으로 좌우 대칭인 분포
05. 표준정규분포(Standard Normal Distribution)



- 확률밀도함수를 모르더라도, X가 특정 구간에 속할 확률을 쉽게 구하기 위해서 또는 평균 & 퍼진 정도를 동일하게 맞추기 위해 정규분포를 표준정규분포로 변환.
- 표준화된 새로운 값을 Z값이라고도 함.
(Examples)
X ~ N(10,4)
Z = (X-10) / 2
Q1.
P(8 ≤ X ≤ 10) =?
P((8 -10)/2 ≤ Z ≤ (10-10)/2)
P(-1 ≤ Z ≤ 0)
06. 누적 분포 함수 (CDF, Cumulative Distribution Function)
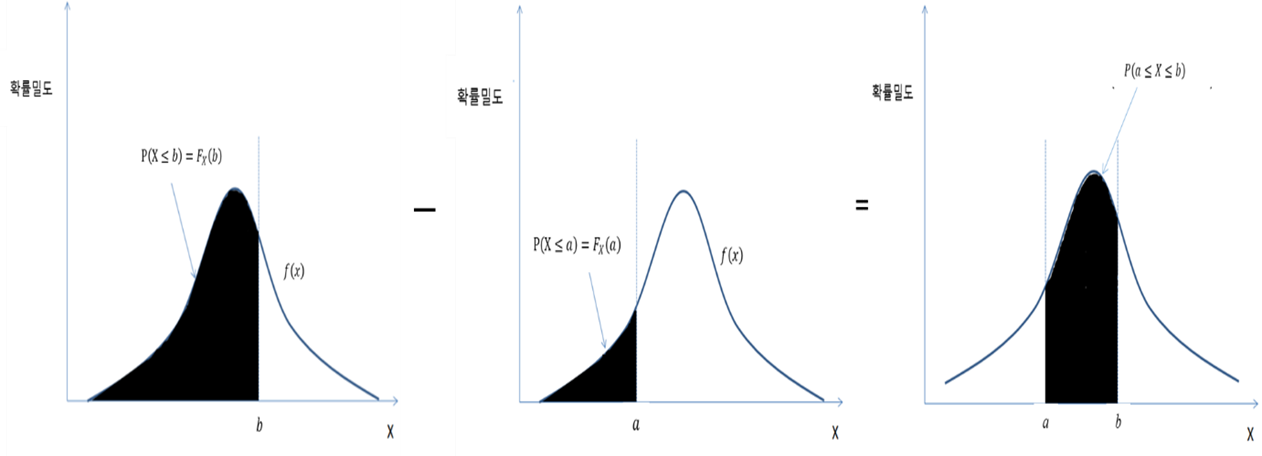
- 누적분포함수를 이용한 P(a ≤ X ≤ b) = P(X ≤ b) - P( ≤ a) = Fx(b) - Fx(a)
- 변수가 특정한 값 이하의 값을 취할 확률을 나타내는 함수
- 0~1 사이의 값


