
01. Seq2Seq란?
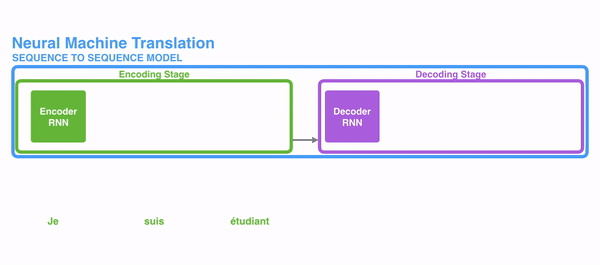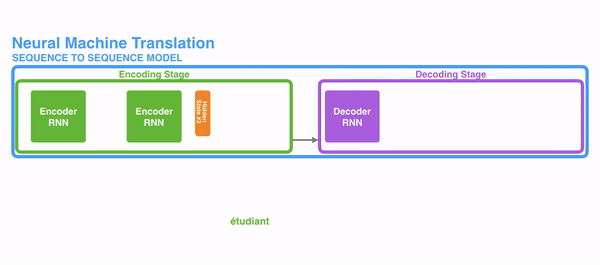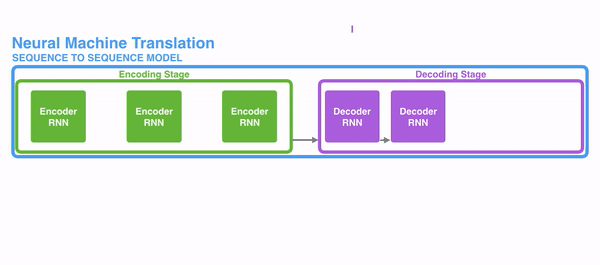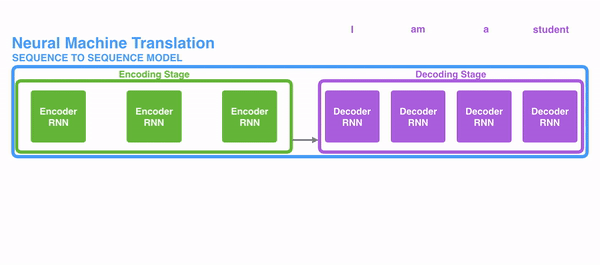
seq2seq는 'sequence to sequence(시계열에서 시계열로)'로, 한 시계열 데이터를 다른 시계열 데이터로 변환하는 것을 의미한다. 기본적으로 seq2seqs는 RNN기반의 모델 두 개를 연결하여 구현할 수 있으며, 이를 encoder(인코더)-decoder(디코더) 모델이라고도 한다. 인코더는 입력된 정보를 취합/저장하는 역할을 하고, 디코더는 인코더로부터 축약된 정보들을 풀어서 반환/생성해주는 역할을 한다. 하나의 문장을 시퀀스로 볼 수 있는데, 이때 어떠한 언어 문장(ex. 안녕!)을 또 다른 언어의 문장(ex.Hi!)으로 번역하는 것이 seq2seq의 대표적인 예이다.

02. Seq2Seq원리
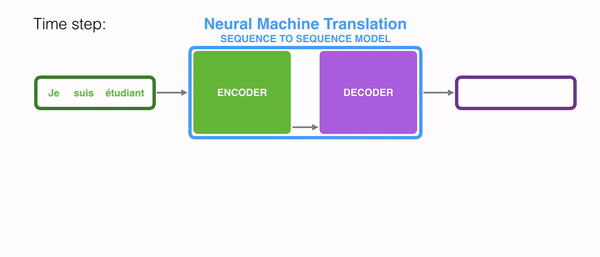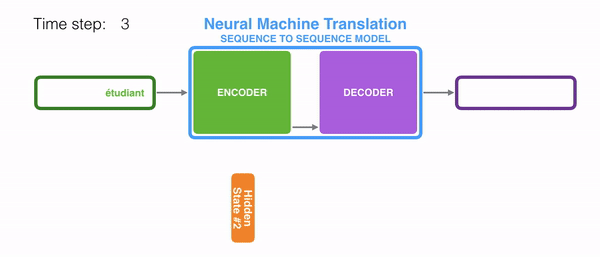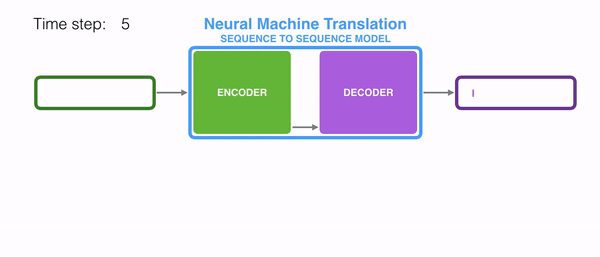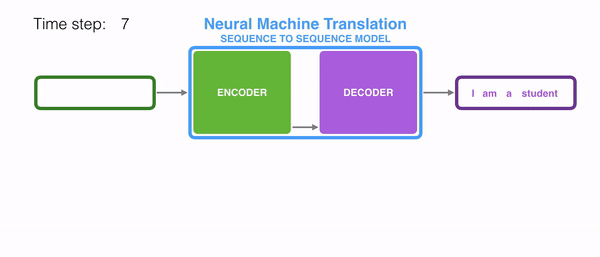
seq2seq는 인코더&디코더라는 두 개의 모듈로 구성된다. 이때 인코더는 입력 시퀀스(문장)의 각 단어들을 순차적으로 입력받아 하나의 고정된 크기의 벡터로 만들며, 이는 seq2seq에서의 가장 중요한 특징이다. 이때 인코더가 출력하는 Hidden state vector는 LSTM계층의 마지막 hidden state이며, 이 벡터를 'context vector'라고 한다. context vector에는 입력 시퀀스의 모든 정보가 담겨있다. 결론적으로 '인코딩한다'라는 것은 임의 길이의 시퀀스를 고정된 길이의 벡터로 변환하는 작업을 의미하는 것이다. 입력된 시퀀스의 정보가 하나의 context vector로 압축되면 이를 디코더로 전달한다. 디코더에서는 전달받은 context vector정보를 이용하여 다른 도메인의 시퀀스로 반환한다. 따라서 context vector가 인코더에 입력된 시퀀스 데이터의 정보를 잘 담아내지 못한다면 성능에도 영향을 미칠 수 있다.
이때 인코더와 디코더의 입력 차원은 서로 다를 수 있으며, 더욱이 인코더와 디코더는 비슷한 아키텍처를 가지고 있지만 서로 다른 파라미터(가중치)를 가진다. seq2seq는 두 개의 RNN으로 구성되는데, 실제로는 성능 문제로 인해 바닐라 RNN이 아닌, LSTM 또는 GRU 등으로 구성된다.
🖇참고문헌
'🤖딥러닝' 카테고리의 다른 글
| loss값이 nan인 이유와 해결 방법 (1) | 2022.07.19 |
|---|---|
| Attention Mechanism (어텐션 메커니즘)의 거의 모든것(1) (0) | 2022.07.18 |
| 다중 분류 손실함수(categorical_crossentropy 와sparse_categorical_crossentropy 차이) (0) | 2022.07.12 |
| [딥러닝] Object detection (2)(R-CNN / Fast R-CNN / Faster R-CNN 총정리) (0) | 2022.01.10 |
| [딥러닝] Object detection(Region proposal / Sliding window / Selective search) (0) | 2022.01.10 |



