
Attention Mechanism (어텐션 메커니즘)의 거의 모든것(1)

01. seq2seq의 문제점
이전 게시글에서는 입력 시퀀스에 대한 모든 정보를 하나의 고정된 크기의 벡터(context vector)로 인코딩한다음, 이를 디코더로 전달하여 다른 도메인의 시퀀스를 출력하는 seq2seq에 대해 정리하였다. seq2seq는 vanilla RNN보다 시퀀스 데이터를 더욱 잘 처리할 수 있지만, 여전히 한계가 존재한다.
1️⃣입력 시퀀스의 길이에 상관없이, 항상 고정된 크기의 벡터에 모든 정보를 압축하기 때문에 이 과정에서 정보 손실이 발생한다. (bottleneck으로 작용)
2️⃣입력 시퀀스의 길이가 길어지면 RNN에서 발생된 기울기 소실(vanising gradient) 문제가 여전히 존재한다.
-> 위와 같은 seq2seq의 문제점을 보완하기 위해 Attention Mechanism(어텐션 메커니즘)이 제안되었다.
02. Attention이란?
Attention의 기본적인 컨셉은 말 그대로중요한 부분에 더 '집중(Attention)'하자! 는 것이다.
'나는 학생이다' 라는 문장을 'I am a student'로 번역하는 과정을 예로 들어보자면, 디코더에서 'student'라는 단어를 (예측)출력할때 인코더에 입력된 단어들 중, 'student'와 관련이 높은 '학생'이라는 단어에 조금 더 '집중(Attention)'해서 참고하여 결과를 내놓자는 것이다.
또한 앞서 언급했듯, 기본적인 seq2seq모델은 인코더에서 입력 시퀀스의 정보를 하나의 고정된 크기의 벡터(context vector)로 압축하여 디코더로 전달하는데 이 과정에서 정보 손실이 발생한다. 뿐만 아니라 context vector는 인코더의 마지막 layer의 hidden state이므로, 마지막 time state의 정보가 더 많이 담기게 되기 때문에 여전히 장기 의존 문제가 발생할 수 있다. (그림 참고 : seq2seq의 원리)
따라서 Attention은 이러한 문제점을 해결하기 위해 인코딩 단계의 마지막 hidden state만 디코더로 전달하는 것이 아니라 인코더의 모든 hidden state를 디코더로 전달한다.(그림 참고: Attention Mechnism의 원리)
2-1. Attention Mechanism에서의 Encoder
Attention Mechanism에서 인코더 부분을 조금 더 자세히 보자면, 위의 그림에서 인코더의 각 time step에 '나' / '는' / '학생' / '이다'라는 4개의 단어가 입력되고 그에 따라 4개의 hidden state vector가 출력되었다. 각 단어의 hidden state vector를 모두 이용하면 입력된 단어와 같은 수의 vector를 얻을 수 있는데(맨 오른쪽 hidden state처럼), 이때 Attention은 인코더의 각 time step에서 출력된 모든 hidden state가 디코더로 전달된다.
2-2. Attention Mechanism에서의 Decoder
이렇게 인코더에서 출력된 모든 hidden state vector가 디코더에 전달되어 시계열 변환이 이루어지는데 이때 기본적인 seq2seq와는 달리 디코더에 Attention layer가 추가된다.
03. Attention Layer
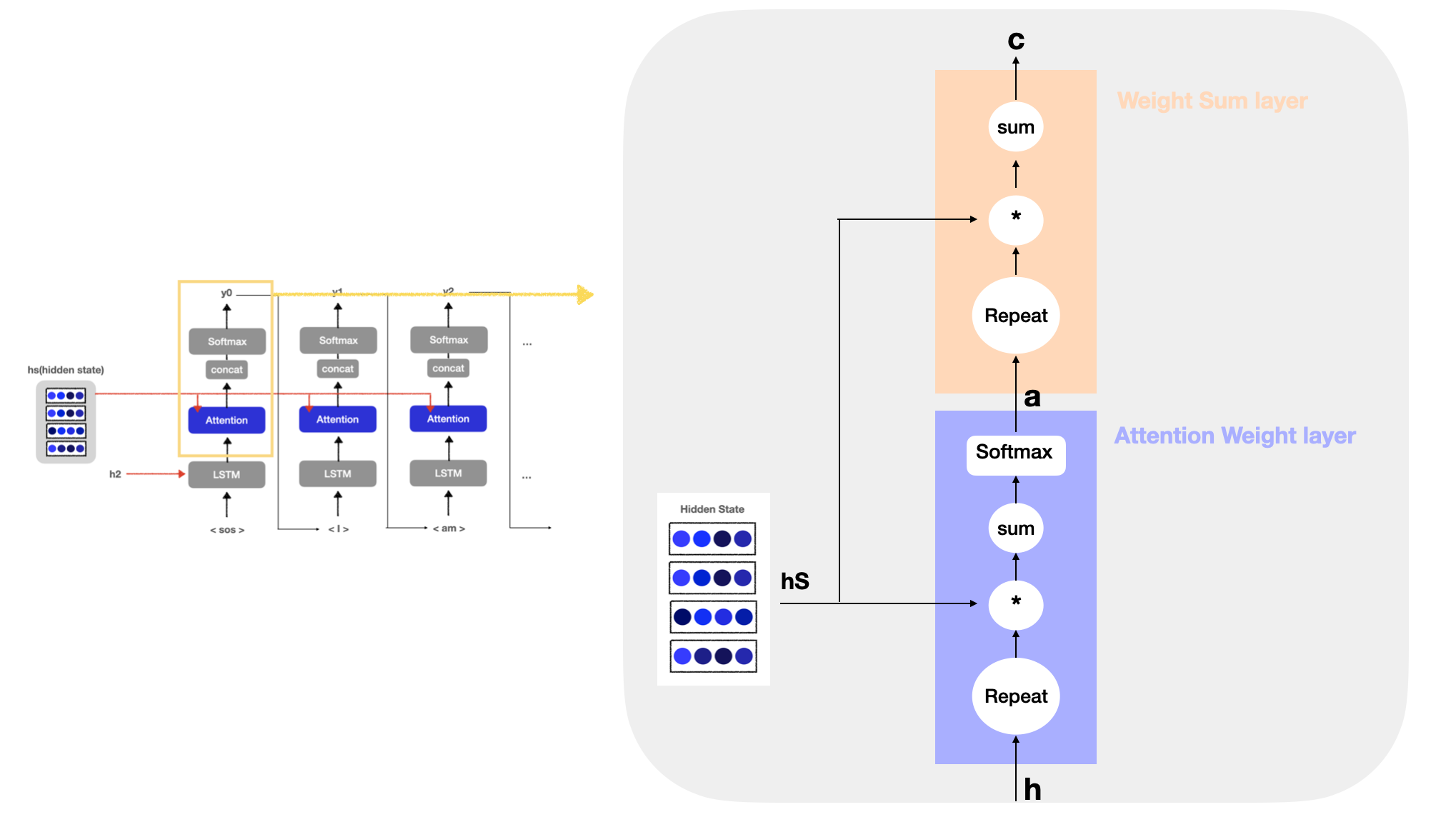
위의 신경망에서 궁극적으로 하고자 하는 것은 단어들의 얼라인먼트(alignment)*를 추출하는 것이다. 즉, 각 time step에서 디코더에 예측하고자 하는 단어와 대응 관계인 단어의 벡터를 hs에서 골라내는 것이 목적이다.
*얼라인먼트(alignment) : 단어의 대응관계를 나타내는 정보
이때 Attention layer는 1️⃣인코더가 출력하는 각 단어 hidden state vector에 주목하여 해당 단어의 가중치(a)를 구하는 Attention Weight layer와 2️⃣a와 hidden state의 가중합을 구하고 그 결과를 맥락 벡터(context vector)로 출력하는 Weight Sum layer로 구성되어 있다. (그림 'Attention layer' 참고)
3-1) Attention Weight layer
Attention Weight layer는 디코더의 LSTM layer에서 출력된 hidden state vector(h)와 인코더에서 넘어온 hidden state vector(hs)를 이용하여 가중치 (a)를 구하는 단계이다. 기본적으로 Attention은 디코더에서 출력하는 매 시점(time step)마다 인코더에서의 전체 입력 시퀀스 정보를 다시 한번 참고하며, 전체 입력 시퀀스를 전부 동일한 비율로 참고하는 것이 아니라 해당 시점에서 예측해야 할 단어와 연관이 높은 입력 단어에 조금 더 '집중(Attention)'해서 참고한다고 했다.
그렇다면, 어떠한 방법으로 해당 단어에 '집중(Attention)'하게 만드는 것일까?
이에 대한 아이디어는 '각 단어의 가중치를 계산하여 이를 반영하자!'는 것인데, 이때의 가중치는 각 단어의 중요도(기여도)를 의미한다. 즉, 인코더에 입력으로 들어오는 단어들 중에서 특정 타임 스텝에서 디코더가 예측하고자 하는 단어와 관련이 높은 단어에 큰 가중치를 부여하는것이다. 예를 들면, 디코더에서 'I'를 예측할 때(y0) 인코더에서 넘어온 모든 hidden state vector 중에서 'I'와 관련이 높은 '나'에 해당되는 hidden state vector에 가장 큰 가중치를 부여한다. 더 높은 가중치를 부여한다는 것은 그만큼 더 '주의(Attention)'를 기울인다는 것으로 볼 수 있으며, 이러한 방식을 통해 디코더에서 예측하고자 하는 단어를 조금 더 정확하게 예측할 수 있게 되는 것이다.
그렇다면, 해당 단어에 얼마나 많은 '주의(Attention)'을 기울일 것인가에 대한 값인 가중치는 어떻게 계산되는 것일까? 결국 두 단어의 연관성이 높기 때문에 주의를 기울이자! 는 것인데, 서로 다른 (hidden state) vector 간의 유사도(연관성)는 어떻게 구할 수 있을까? 벡터간의 거리(유사도)를 구하는 방법으로는 내적 / 코사인 유사도 / 유클리디안 거리 방법 등이 있지만, 그중 내적을 이용하는 것이 가장 속도가 빠르며 간단하기 때문에 기본적으로 많이 사용된다. 내적의 직관적인 의미는 '두 벡터가 얼마나 같은 방향을 향하고 있는가?'로 이해할 수 있다. 따라서 두 벡터(단어)의 '유사도'를 내적으로 표현할 수 있기 때문에, 디코더에서 예측을 하고자 하는 단어에 대한 hidden state vector와 인코더에서 전달된 hidden state vector들 간의 내적 연산을 통해 유사도를 측정한다.

위의 예시를 보자면,
'나는 학생이다'라는 하나의 문장에서 각 단어들은 4차원 벡터 형태로 표현되어있고 각각의 단어에는 가중치가 곱해져 있다.
이때, Attention Weight layer에서 출력되는 값은
= ( 0.1 0 0 0.1 ) + (0.055 0 0 0.11) + ( 0.8 0.8 1.6 0 ) + ( 0.045 0.045 0 0 )
으로 계산하면 된다.
이렇게 Attention Weight layer에서 출력된 vector를 'Attention score'라고 한다. Attention score는 서로 다른 hidden state 간의 유사도를 의미하므로, Attention score가 클수록 두 벡터간의 유사도가 크다는 의미이다. 이때 Attention score를 직접적으로 가중치로 사용하지 않고, 정규화시키는 과정이 필요하다. 따라서 정규화를 위해 (일반적으로) softmax함수를 적용하여 각 가중치를 0~1 사이의 확률 값으로 만든다.
3-2) Weight Sum layer
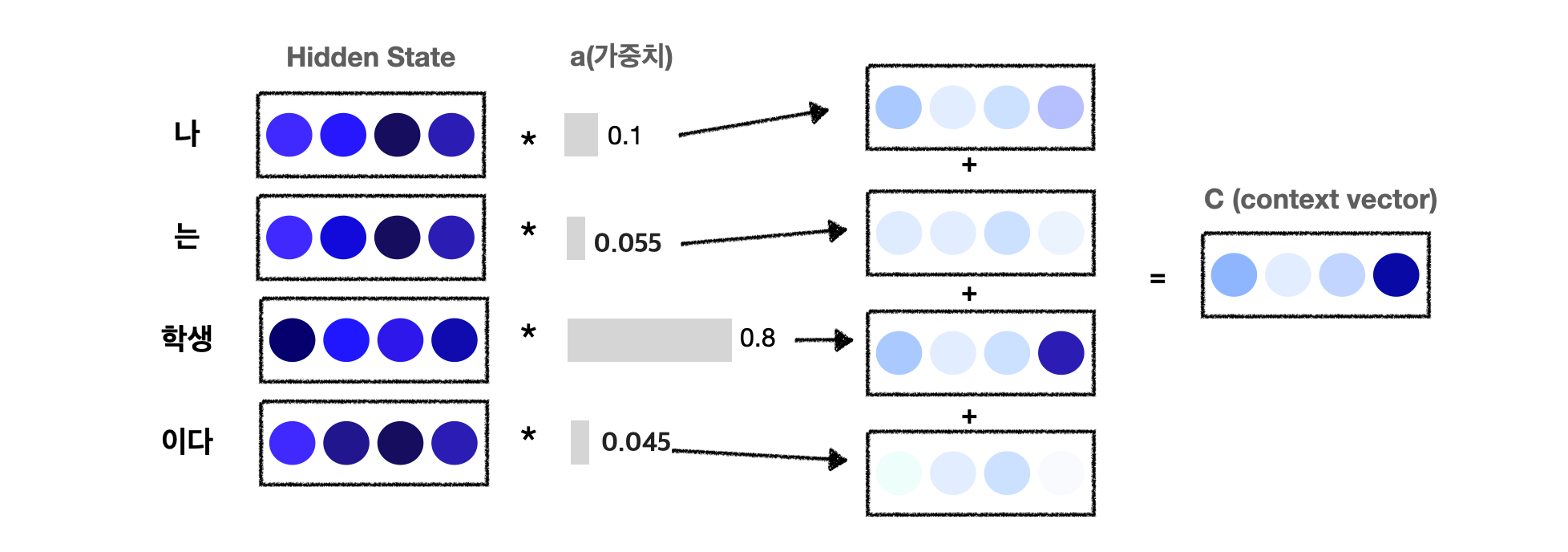
Weight sum layer에서는 1️⃣각 단어의 중요도를 의미하는 가중치(a)와 2️⃣각 단어의 hidden state의 가중합(weighted sum)을 통해 맥락 벡터(context vector)를 출력한다. 위의 그림을 보면 '학생'에 대응하는 가중치가 0.8으므로, 맥락 벡터(C)에는 '학생'이라는 단어의 성분이 많이 포함되어있게 된다. 즉, 가중합을 통해 '학생'이라는 벡터를 선택하는 것으로 해석할 수 있다.
🖇참고문헌
'밑바닥부터 시작하는 딥러닝2'