[논문 리뷰] The 12-lead electrocardiogram as a biomarker of biological age (심전도 데이터를 활용한 사망위험 예측 분석)

01. Introduction
이전 연구들에서 심전도(ECG) 데이터를 활용하면 각 사람을 식별할 수 있으며(지문과 같은 생체 정보로서의 기능), 뿐만 아니라 개인의 나이도 예측할 수 있다는 것이 밝혀졌다. 하지만 심전도로 나이를 예측하는 과정에서 대상자의 실제 나이와 심전도로 예측된 나이에 약간의 차이가 발생할 수 있다. 따라서 본 연구에서는 ECG로 단순히 나이를 예측하는 것을 너머, 실제 나이와 신체 나이 간의 차이를 노화 관련 지표로 설정하고 이러한 차이에 따른 심혈관계 사망률을 분석하고자 한다.
연구에서 사용된 'age'개념은 크게 두가지로 나눌 수 있다.
1) Chronological age : 이는 대상자가 단순히 얼마나 오랜 기간 살았는가를 의미하며, 흔히 말하는 '주민등록상의 나이'라고 생각하면 된다.(Chronological age simply represents how long an organism has been alive)
2) Biological age : 쉽게 생각하면 신체 나이로, 객관적으로 전반적인 건강상태와 노화 정도를 나타낸 지표이다.(Biological age, alse referred to as physiologic age, on the other hand, refers to the gradual decline in an organism's functional status-the clearest measure of which is mortality)
또한 Chronological age와 Biological age의 차이를 'Age-Gap'이라는 용어로 정의하고 이 'Age-Gap'이 음/양의 방향으로 얼만큼 차이가 나는지에 따른 사망률 변화를 분석한다.
*Age-Gap = (Biological age(ECG-derived ages) - Chronological age)
* keywords : ECG age / Biological age / Mortality
02. Methods

연구 설계는 다음과 같다. 12-lead의 ECG data가 model의 input으로 들어오면, model은 그에 따른 'age'를 예측하여 output으로 내놓게 된다. 이때 대상자의 실제 나이(Chronologic age)보다 ECG data로 예측된 값(Biological age)이 더 많다면 mortality가 증가하고, Biological age가 더 낮다면 mortality가 감소한다. 즉, 대상자의 실제 나이보다 ECG로써 예측된 신체 나이가 더 많다면(그리고 그 차이가 커질수록) 기하급수적으로 사망 위험이 증가하게 된다.
1) Study Population

연구는 관상동맥 질환이나 뇌졸종 및 심방세동을 앓고 있는 사람등을 제외하고 약 2만 5천 명의 대상자를 선정하여 진행되었다.
2) Model - 1D CNN

본 연구에서는 age를 예측하기 위해 1D CNN model를 적용하였고, 모델의 전체적인 구조는 다음과 같다. 첫 번째 블록은 데이터의 시계열적인 특성을 추출하는 기능을 수행하고, 두 번째 블록에서는 12개의 모든 리드를 융합하는 기능을 하며, 최종적로 Fully connected 블록을 거쳐 ouput을 내게 된다.

Model 구조를 조금 더 자세히 보자. 기본적으로 CNN모델은 input layer, convolution layer, fully connected layer 그리고 output layer로 구성되어 있다.
먼저, input으로 3차원 형태의 ECG data가 들어오게 된다. 그리고 Convolution layer에서는 이러한 입력 이미지에 커널(필터)을 적용한다. 커널은 가중치가 담긴 행렬로, 해당 이미지에서 feature를 추출하는 역할을 한다. 이렇게 이미지에 커널을 적용시킨 결과로 하나의 feature map이 생성되며, feature map의 depth는 이미지에 총 몇 개의 커널을 적용했느냐에 따라 결정된다.
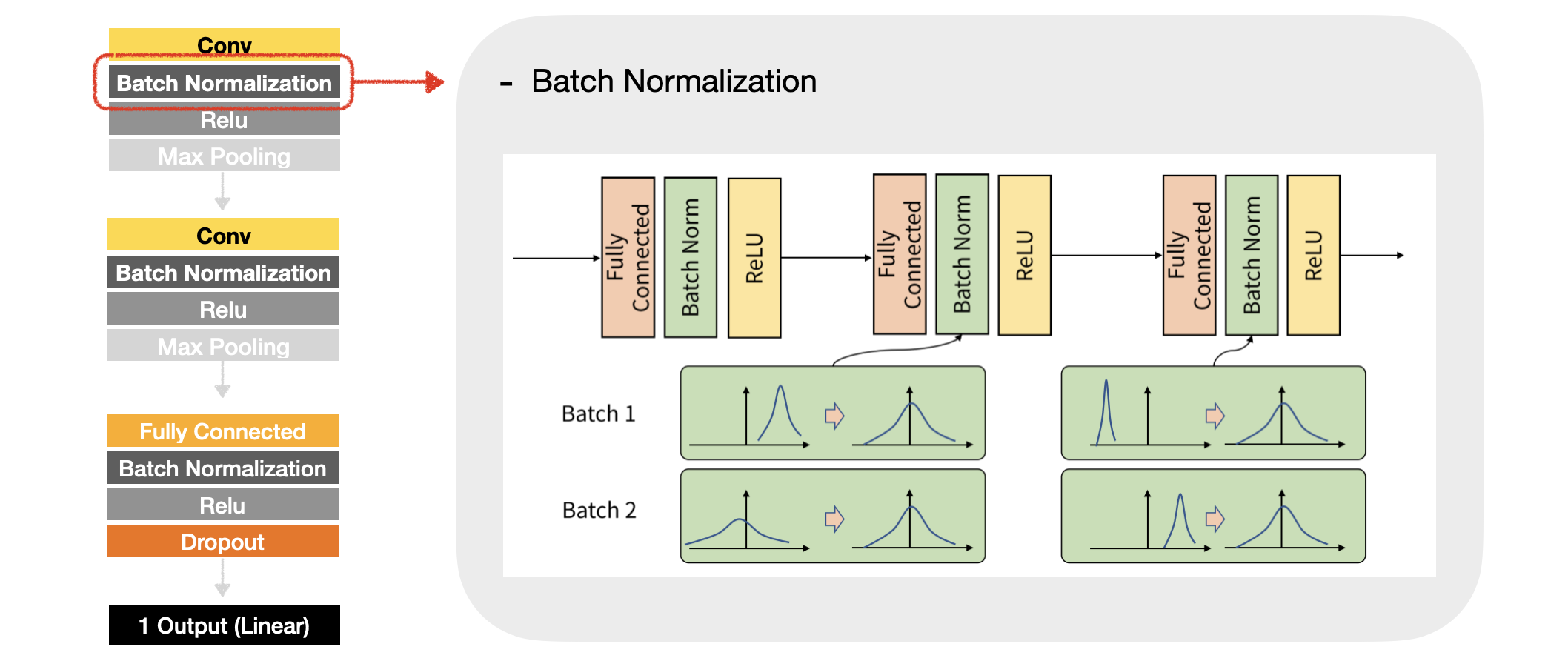
생성된 feature map에 배치 정규화를 적용한다. 배치 정규화는 hidden layer에서의 노드들이 항상 표준 분포를 따르도록 만들어주는 방법으로, 배치 정규화를 적용해 주면 앞층의 출력이 항상 같은 평균과 분산을 갖게 되므로, 뒷층의 관점에서는 입력이 크게 흔들리지 않아 학습이 쉬워진다는 장점이 있다.
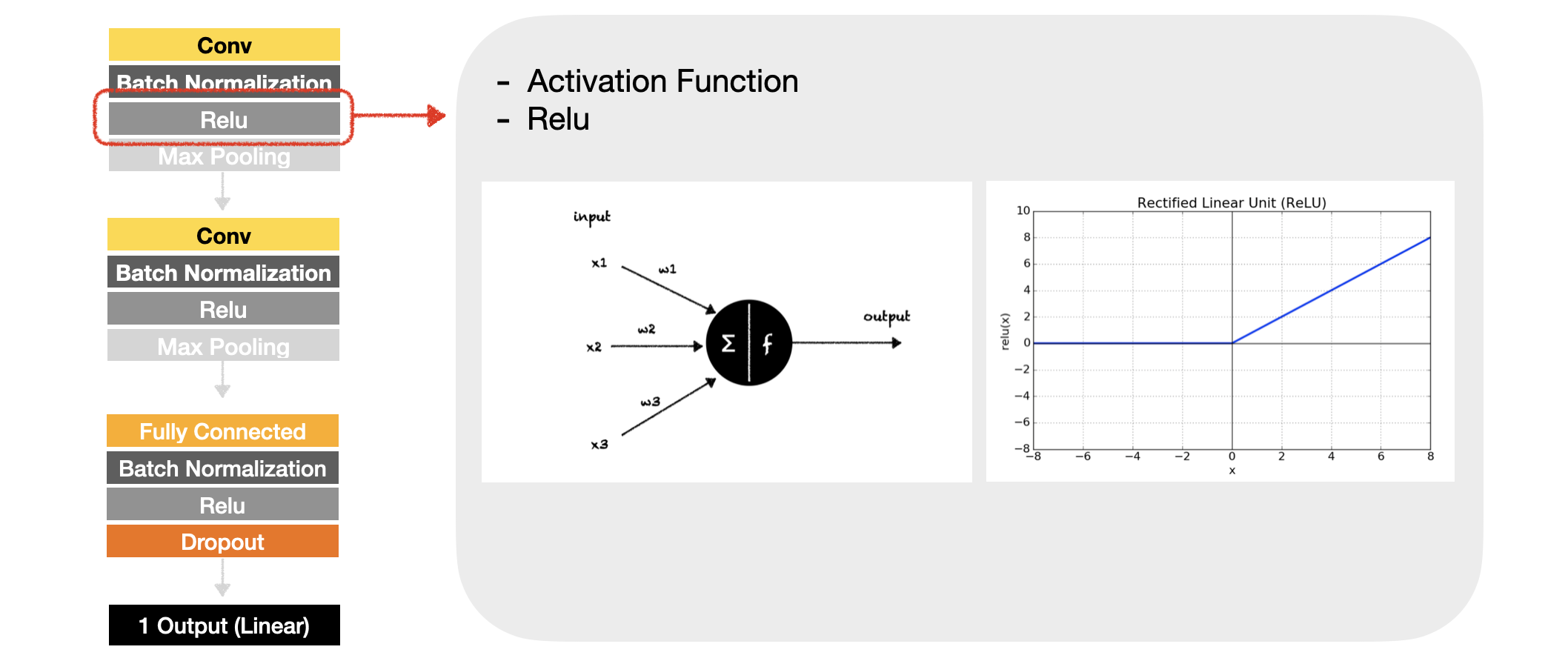
모델에서는 배치 정규화의 다음단계로 activation function을 적용한다. activation function은 노드에 어떠한 input이 들어왔을 때, 그 값을 다음 layer의 노드로 넘길지 말지, 그리고 넘긴다면 얼마큼의 값으로 넘길지를 판단하는 역할을 한다. 만약 이러한 활성화 함수가 없는 딥러닝 모델의 경우, 아무리 layer를 깊게 쌓아도 그 모델은 하나의 layer로 구성된 네트워크와 다를 바 없어진다. 하지만 우리가 실제로 풀고자 하는 문제들은 굉장히 복잡한 테스크이므로 활성화 함수를 적용하여 모델이 복잡한 문제들도 잘 풀 수 있게 해 주는 것이다. 활성화 함수의 종류는 굉장히 다양한데, 이 연구에서는 Relu function을 적용하였다.
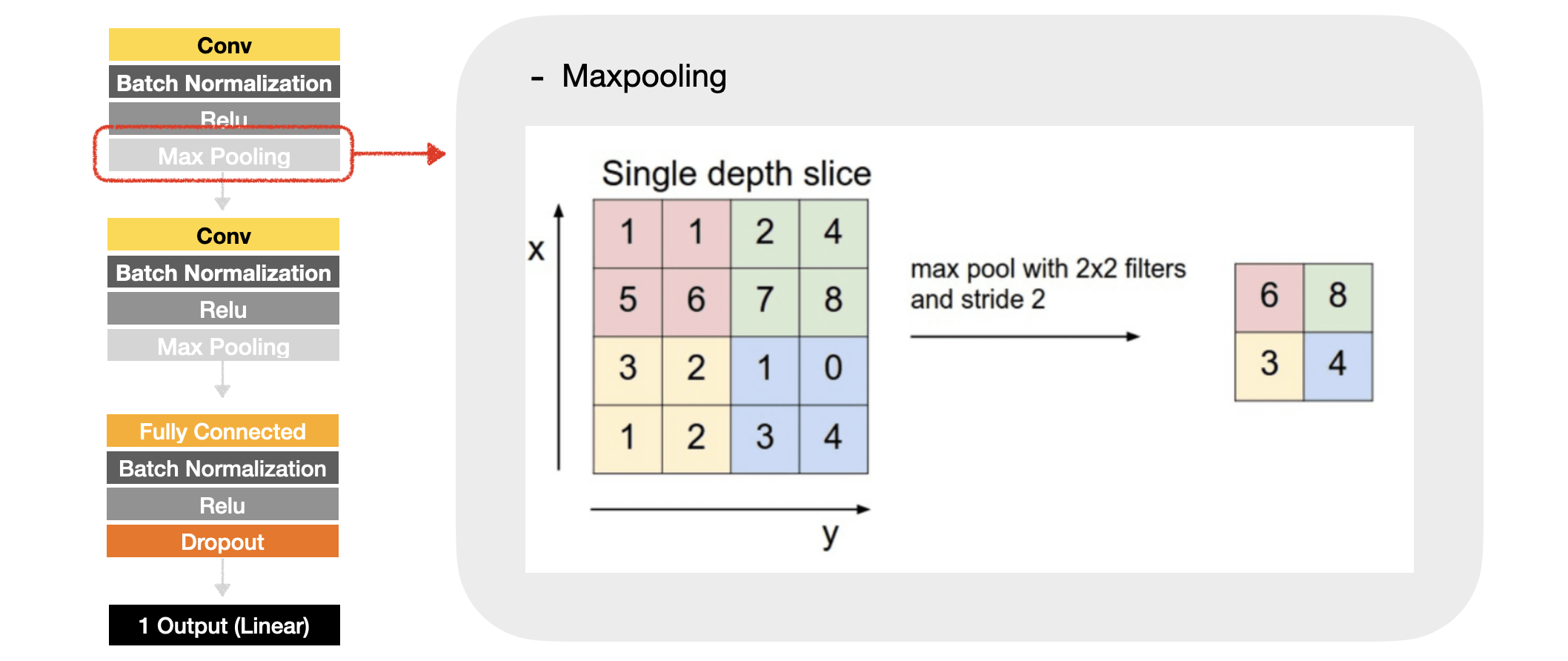
블록의 마지막으로는 Poooling layer가 있다. Convolution layer가 많아질수록, 학습해야 할 파라미터수가 드러나게 되는데, 그만큼 학습과정에서의 계산 복잡도가 증가하고 소요 시간이 오래 걸리게 된다. 따라서 Pooling layer에서 계산 복잡도를 낮추는 것이다. 해당 연구에서는 max pooling을 적용하였는데, 이는 적용된 필터 부분에서 max 값만을 추출하면서 pooling을 진행하는 방식이다.
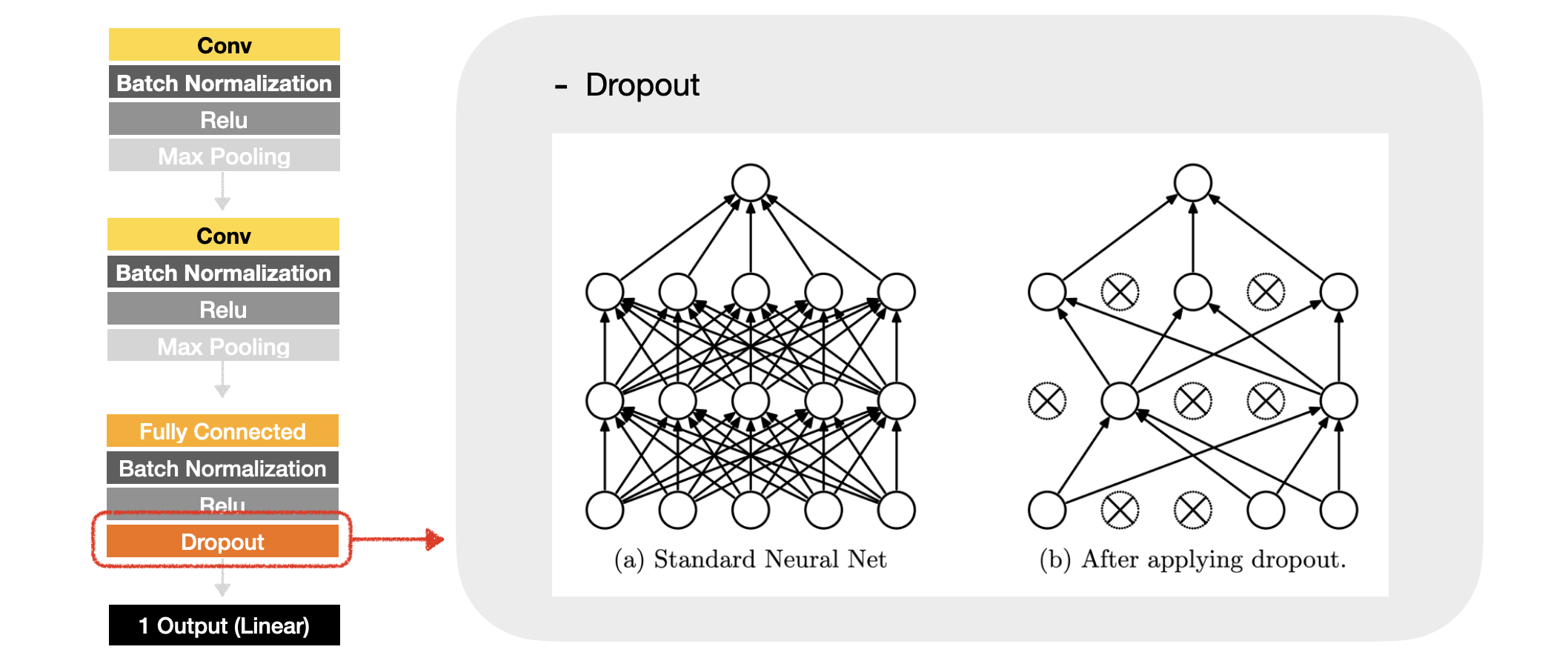
이러한 방식으로 convolution 블록에서는 feature를 추출고 적절하게 크기를 조절해 나가는 작업이 반복적으로 수행되고, 그다음 fully connected layer를 거치게 된다. fully connected layer에서는 모델의 오버피팅을 방지하기 위한 기법으로 드롭아웃을 적용한다. 드롭아웃이란, 모델이 학습하는 과정에서 임의로 특정한 비율의 노드를 비활성화시키는 방식이다.
해당 과정들을 모두 거쳐 output layer에 도달하게 되는데, output layer의 노드수는 내가 풀고자 하는 문제에 따라 설정해 주면 된다. 이번 연구의 경우 ECG data가 input으로 들어왔을때, 그에 따라 하나의 수치값인 'age'를 예측하는것이 목표이므로, 노드를 1로 설정해주면 된다.
03. Results
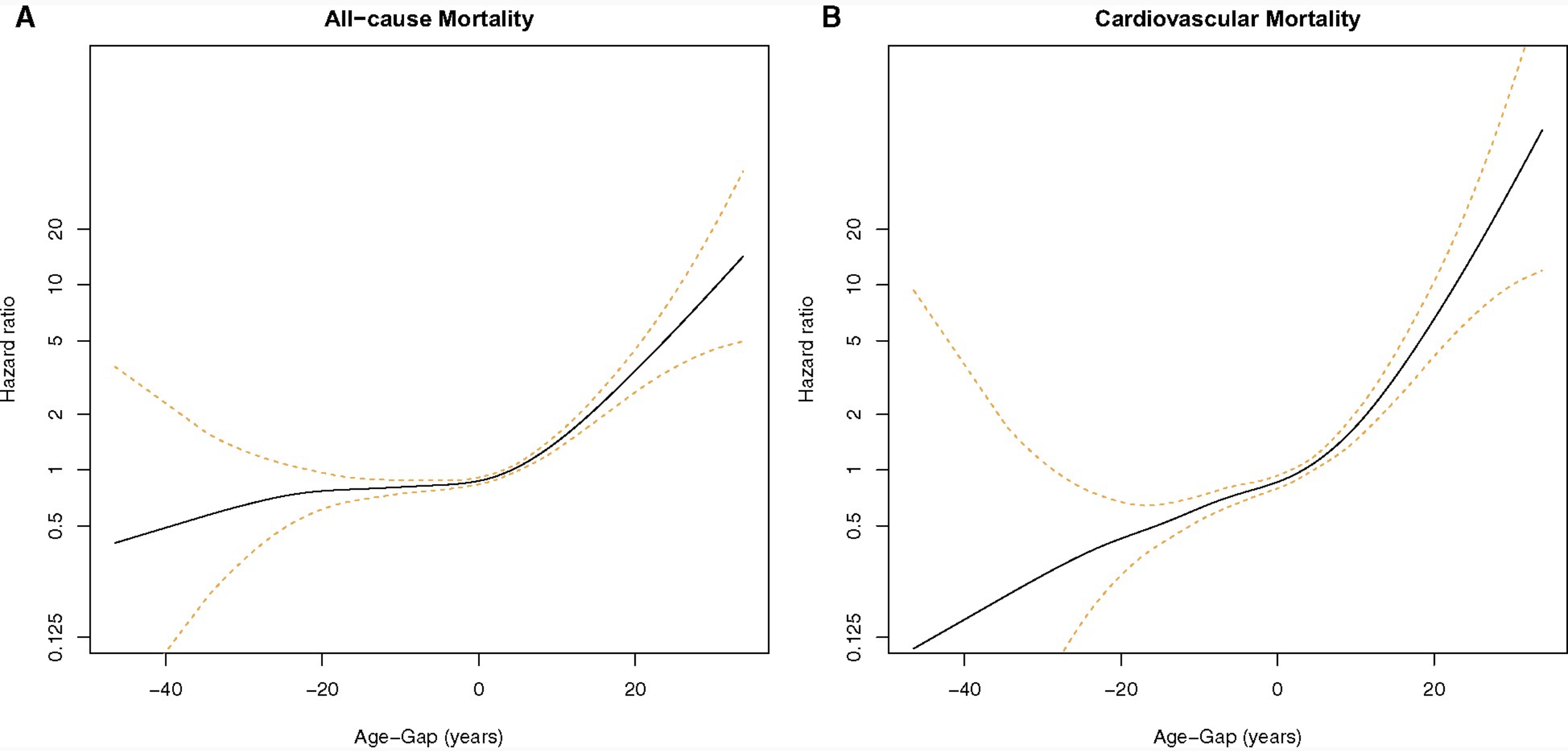
그림 2에 따르면, Age-Gap이 +1SD인 사람은 All-cause mortality가 증가한 반면, Age-Gap이 -1SD인 사람들은 감소했다.
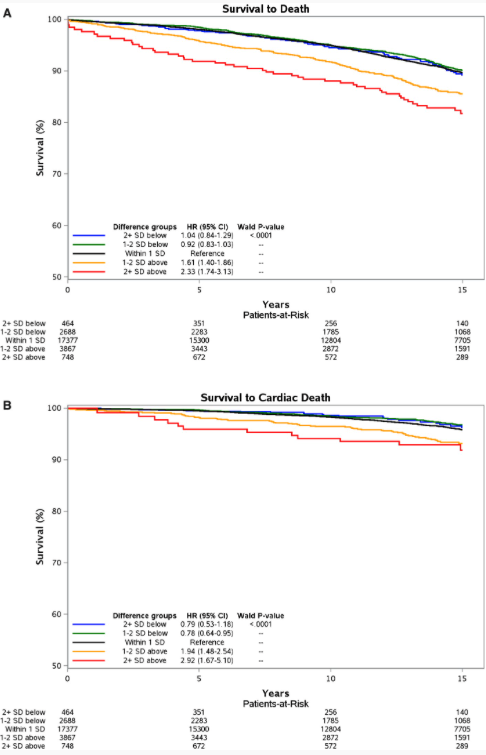
Figure3 A. 에 따르면, Age-Gap(ECG derived age - Chronological age) 이 +1SD보다 큰 대상자는 모든 원인에 대해 사망 위험이 증가한 반면, Age-Gap이 -1SD보다 작은 대상자들은 사망 위험이 감소했다. 즉, 대상자의 실제 나이(chronological age)보다 ECG-derived age가 크면 클수록 사망위험이 급격히 증가한다는 의미이다.
https://academic.oup.com/ehjdh/article/2/3/379/6248088?login=true
https://www.ahajournals.org/doi/full/10.1161/circep.119.007284(모델 레퍼런스 논문)