Sleep-EDF dataset (python에서 EDF 포맷 읽기)

01. Sleep-EDF dataset
Sleep-EDF dataset은 EEG(Fpz-Cz 및 Pz-Oz), EOG, EMG 및 이벤트 마커가 포함된 197개의 수면다원검사(Polysomnographic) 기록이 포함되어있는 오픈 데이터셋이다.
Sleep-EDF dataset을 다운로드하면 크게 두 가지 종류의 폴더가 있다.
1) Sleep-cassette
2) Sleep - telemetry
1) Sleep-cassette는 시간순으로 PSG의 각 센서 데이터의 기록이고,
2)Sleep-telemetry는 테마제팜(temazepam)이라는 불면증 치료제 효과를 확인하기 위해 만든 데이터 셋이다.
이 중, 1)sleep-cassette dataset을 활용하여 edf파일을 읽어오는 방법을 정리해보고자 한다.
02. EDF 포맷

Sleep-EDF dataset을 다운받아 폴더를 열어보면 각 파일들이 .edf형식으로 되어있는 것을 알 수 있다.
EDF는 유러피언 데이터 포맷(European Data Format)으로, 의료 시계열의 교환 및 저장을 위해 설계된 표준 파일 형식이다. EDF는 수면다원검사(PSG) 기록에 널리 사용되는 형식으로, 내부적으로는 Header와 하나이상의 데이터 레코드를 포함한다.
03. python에서 EDF 파일 불러오기
from pyedflib import highlevel
import pandas as pd
import numpy as np
import numpy as np
from glob import globdata_list = glob('*.edf')
trains = [x for x in data_list if x.endswith('PSG.edf')]
labels = [x for x in data_list if x.endswith('Hypnogram.edf')]
data_list
glob로 각 파일들을 불러온 뒤,
data_list를 확인해보면 PSG(수면다원검사)와 Hypnogram파일들이 있는 것을 확인할 수 있다.
〰️highlevel.read_edf( )
1) train set 살펴보기
highlevel.read_edf(trains[0])
이번에는 highlevel.read_edf()를 활용하여 trains데이터셋의 [0] 값을 출력해보자
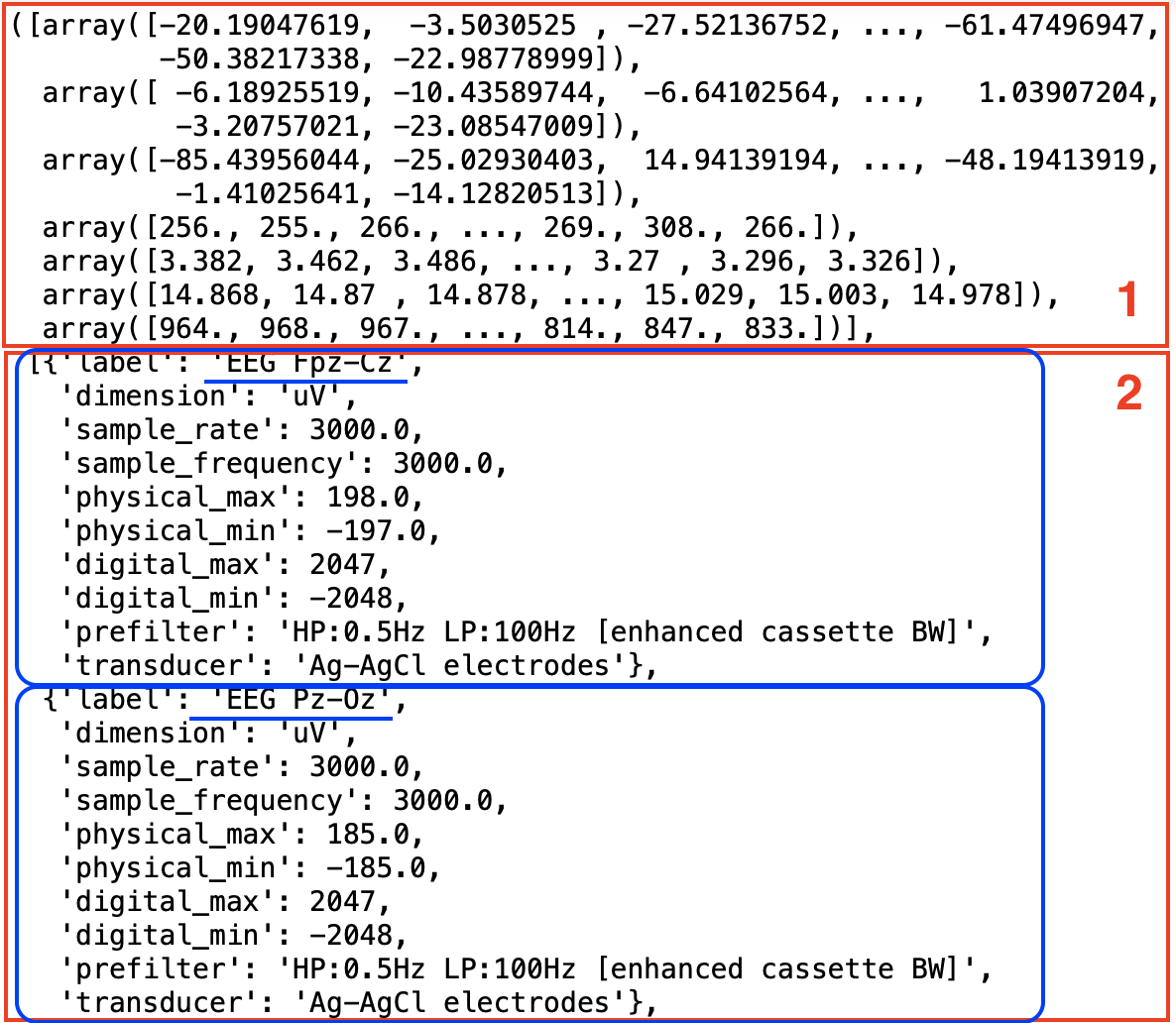
각 환자들의 EEG, EOG, EMG값들이 들어있는 trains set에서
[0] 번째 데이터(즉, 첫 번째 사람)의 값을 출력해보자.
이때 출력된 값은 1) array형식의 센서 데이터들(EEG, EOG, EMG)의 값과
2) 각 센서 데이터들의 정보들(sample_rate, dimension 등)이 json형태로 담겨있다.
highlevel.read_edf(trains[0])[0]
이때, highlevel.read_edf(trains [0])[0]을 출력하면
array부분 즉, 각 센서별 데이터 값들만 선택해올 수 있다.
highlevel.read_edf(trains[0])[1]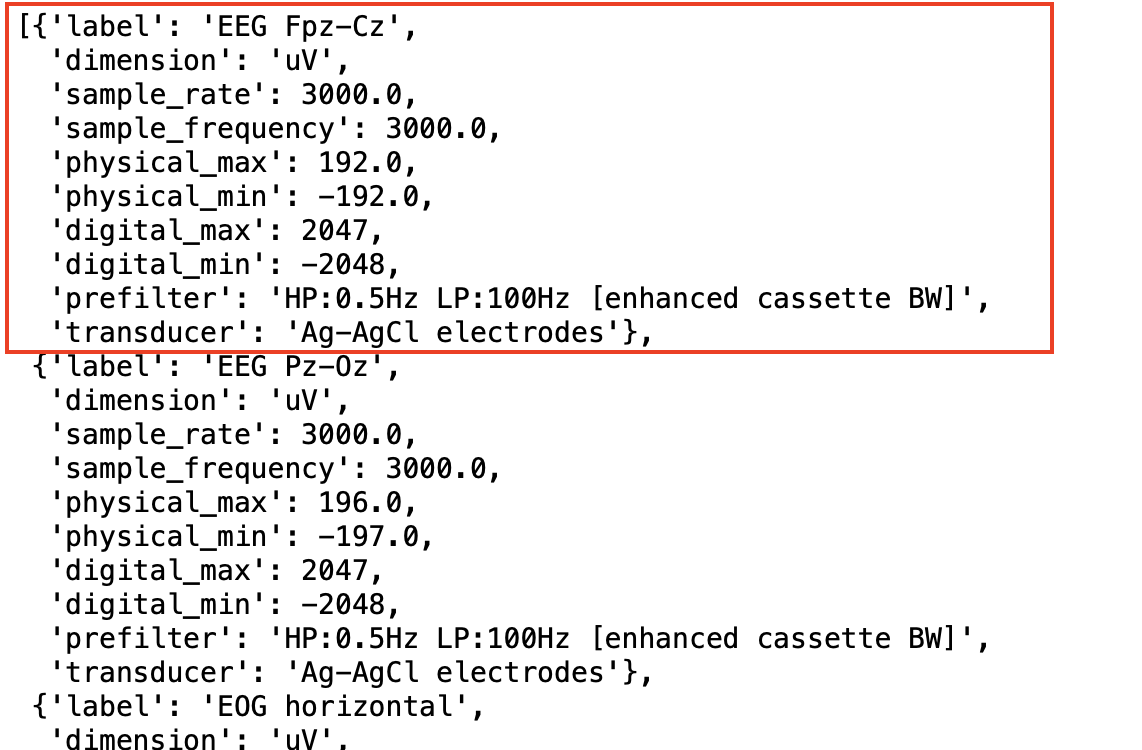
highlevel.read_edf(trains [0])[1]을 적용하면
trains [0] 중, 각 센서들의 정보가 담긴 부분만 선택적으로 가져올 수 있다.


이때, 첫 번째 array의 값은 EEG Fpz-Cz라는 의미로 해석하면 되고,
해당 센서에 대한 정보는 위와 같다.
이러한 방법으로 자신에게 필요한 센서만 추출하여 사용하면 된다.
df = pd.DataFrame(highlevel.read_edf(trains[0])[0]).T
df.columns = ['EEG Fpz-Cz','EEG Pz-Oz','EOG horizontal','Resp oro-nasal',
'EMG submental','Temp rectal','Event marker']
df
각 array형식의 센서 데이터들을 보기 쉽게 하기 위해 pd.DataFrame()으로 데이터 프레임 형식으로 변환하고,
각 칼럼명을 센서명으로 변환해주었다.
2) label 살펴보기
highlevel.read_edf(labels[0])
이번에는 label data를 불러와 확인해보자.
label data에는 시간, duration, sleep stage 정보가 담겨있다.
highlevel.read_edf(labels[0])[2]['annotations']
labels의 정보중, annotations 정보만 추출하였다.
df1 = pd.DataFrame(labels)
df1.columns = ['time', 'duration', 'sleep_stage']
df1
annotations를 조금 더 보기 편하기 위해 데이터 프레임 형식으로 바꿔주었다.
위의 출력 데이터는
0초부터 24390초까지는 'sleep stage w'에 해당된다라는 의미로 해석하면 된다.
df1['sleep_stage'].value_counts()
value_counts()를 사용하여 sleep_stage별 개수를 확인해보자

참고로 PSG(수면다원검사)에서의 sleep stage는
W = 'wake'
NREM단계(sleep stage 1,2,3,4)
REM
기본적으로 이러한 단계로 나누어진다.
🖇데이터 다운 사이트