[머신러닝] 모델 성능 평가 지표 (회귀모델, 분류모델)

1. 모델 성능 평가
- 모델 성능평가란, 실제값과 모델에 의해 예측된 값을 비교하여 두 값의 차이(오차)를 구하는 것
- (실제값-예측값) =0 이 되면 오차가 없는 것으로, 모델이 값을 100% 잘 맞췄다고 생각하면 된다.
- 하지만 예측 값이 실제값과 100% 일치하는 것은 현실적으로 힘들기 때문에, 오차를 구해서 어느 정도까지 오차를 허용할지 결정하게 된다.
- 모델 평가를 하는 목적은 과적합(Overfitting) 방지하고 최적의 모델 찾기 위해 실시한다.
- 모델 성능 평가는 결과변수(답안지)가 있어야 잘한 건지 아닌지 확인할 수 있기 때문에 지도학습에서만 사용할 수 있다.
- 모델링의 목적 또는 목표 변수의 유형에 따라 다른 평가지표를 사용한다.
- Training과 Validation값이 거의 일치해야 좋은 모델이다. 만약 Training데이터로는 성능이 좋게 나왔는데, Validation 데이터를 사용했을 때 성능이 확연하게 떨어진다면 모델이 과적합된 상태이다.
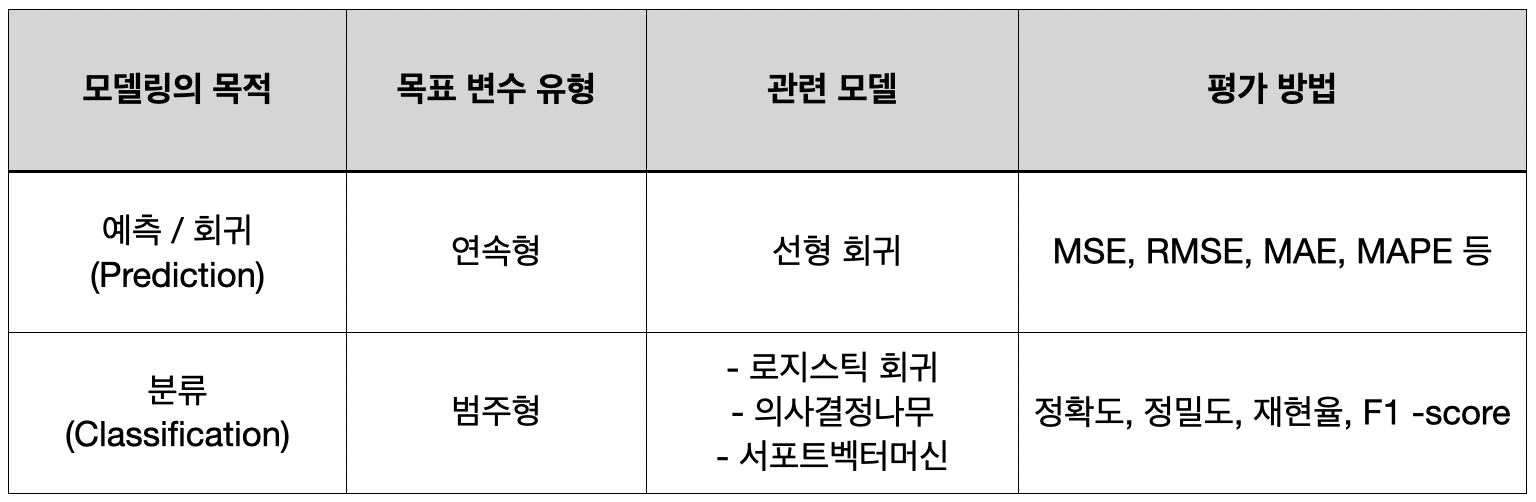
2. 예측 모델 성능 평가
회귀 모델의 평가 지표로는 MSE, RMSE, MAE, MAPE 등이 있으며, 이러한 값들은 결국에는 오차(Error)이기 때문에 그 값이 작을수록 해당 모델의 성능이 좋다는 것을 의미한다.
➰ MSE(Mean Squared Error : 평균 제곱 오차)
: 실제값과 예측값의 차이를 제곱해 평균한 것

➰ RMSE(Root Mean Squared Error : 평균 제곱근 오차)
:MSE값은 오류의 제곱을 구하므로, 실제 오류의 평균보다 값이 더 커지는 특성이 있으므로, MSE에 루트를 씌운 것
- sklearn에서 제공되지 않음

➰ MAE(Mean Absolute Error : 평균 절대 오차)
: 실제 값과 예측값의 차이를 절댓값으로 변환해 평균한 것

➰ MAPE(Mean Absolute Percentage Error : 평균 절대비율 오차 )
: MSE, RMSE의 단점을 보완
-sklearn에서 제공되지 않음
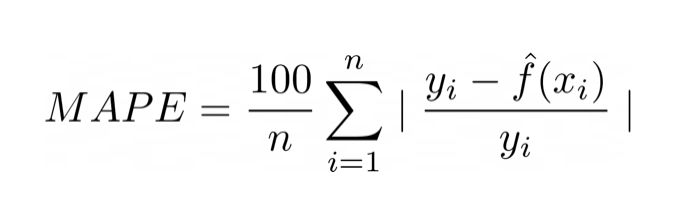
3. 분류 모델 성능 평가
하나의 목표를 가지고 여러 가지 분류 모델을 만드는 경우가 있는데, 그중 어떤 모델이 가장 나을지 판단할 때 이러한 모델 평가지표를 사용하게 된다. 분류 모델의 평가 방법도 회귀 모형과 비슷하게, 실제 데이터와 예측 결과 데이터가 얼마나 서로 비슷한지에 기반하지만, 단순하게 이것만 가지고 판단하기에는 무리가 있다.
분류 모델의 성능 평가하기 위해 다음과 같은 지표를 활용한다.
1) 정확도(Accuarcy)
2) 오차 행렬(Confusion Matrix)
3) 정밀도(Precision)
4) 재현율(Recall)
5) F1-score
6) ROC - AUC
3-1 정확도(Accuarcy)
정확도는 '전체 데이터중에, 정확하게 예측한 데이터의 수'라고 할 수 있다. 하지만 정확도를 분류 모델의 평가 지표로 사용할 때는 주의해야 하는데, 특히 불균형한 데이터(imbalanced data)의 경우에 정확도는 적합한 평가지표가 아니다.
정확도 = TP + TN / TP + TN + FP + FN
3-2 오차 행렬(Confusion Matrix)
오차 행렬은 분류의 예측 범주와 실제 데이터의 분류 범주를 교차 표(Cross Table) 형태로 정리한 행렬이다. 뿐만 아니라 이진 분류의 예측 오류가 얼마인지와 더불어 어떠한 유형의 예측 오류가 발생하고 있는지를 함께 나타낸다.
(파이썬과 R에서 예측값-실제값의 위치가 다름, 아래 표는 파이썬 기준)

3-3 정밀도(Precision)
정밀도는 '양성으로 판단한 것 중, 진짜 양성의 비율'이다.
정밀도 = TP / TP + FP
3-4 재현율(Recall) = 민감도(Sensitivity)
재현율은 '진짜 양성인 것들 중에서, 올바르게 양성으로 판단한 비율'이다. 양성 결과를 정확히 예측하는 능력으로, 모델의 완정 성을 평가하는 지표로 사용된다.
재현율 = TP / TP + FN
정밀도와 재현율은 Positive 데이터 세트의 예측 성능에 좀 더 초점을 맞춘 평가 지표이며, 이진 분류 모델의 업무 특성에 따라 특정 평가 지표가 더 중요한 지표로 간주될 수 있다. 예를 들어 재현율은 실제 Positive(양성)인 데이터 예측을 Negative로 잘못 판단하게 되면 업무 상 큰 영향이 발생하는 경우 더 중요한 지표로 간주되고, 정밀도는 실제 Negative(음성)인 데이터를 Positive로 잘못 판단하게 되었을 때 큰 문제가 발생되는 경우 더 중요한 지표로 간주된다.
재현율과 정밀도 모두 TP(True Positive)를 높이는데 초점을 맞추지만, 재현율은 FN(실제 Positive 한 것을 negative로 예측)한 것을 낮추는데, 정밀도는 FP를 낮추는데 초점을 맞춘다. 이와 같은 특성 때문에 재현율과 정밀도는 서로 보완적인 지표로 분류 성능을 평가하는 데 사용되는데, 이때 어느 한쪽을 강제로 높이면 다른 하나의 수치는 떨어지기 쉬워진다. 이를 정밀도/ 재현율은 트레이트 오프(Trade-off) 관계에 있다고 한다.
3-5 F1 Score
F1 Score는 정밀도와 재현율을 결합하여 만든 지표이다. 정밀도와 재현율이 어느 한쪽으로 치우치지 않는 수치를 나타낼 때 F1 Score는 높은 값을 가지게 된다.
F1 Score = 2 * Precision * Recall / (Precision + Recall)
정확도, 정밀도, 재현율, F1-Score는 모두 0~1 사이의 값을 가지며, 1에 가까워질수록 성능이 좋다는 것을 의미한다.